Рубрика: Общий курс для начинающих
Начало программирования вообще с нуля. Часть 1
В этой статье пойдет речь с чего начать вообще программировать, не важно на каком языке, базовые основы.
К моменту прочтения этой статьи, вам желательно иметь навыки продвинутого пользователя. Это действительно необходимо, в ином случае вы несколько спешите заниматься программированием и даже погружаться в этот мир, так как сложно объяснить что такое спидометр, если человек не знаете в чём измеряется расстояние и как выглядят часы. Однако, если вы способны самостоятельно найти и прочитать в Дзене эту статью, то будьте уверены – вы на правильном пути, и понемногу уже можно начинать)).
Компьютеры сейчас практически в любых электронных устройствах – стиральные машины, холодильники, утюги, термометры, не говоря уже о мобильниках, моноблоках и т.п. В среде информационных технологий это принято называть ёмким словом «железо», а у программистов принято называть «устройство». С точки зрения программирования, компьютер – это обычный калькулятор с расширенным набором функций. Единственное, что отличает его от калькулятора, это то, что в компьютере вы одной командой можете запустить выполнение сразу миллиарда различных действий, а в калькуляторе только одно (умножить, разделить и т.д.). Такое получается по тому, что в любом компьютере действия выполняются по программе, т.е. заранее подготовленной последовательности команд. Вы их подготовили, убедились, что всё верно, и запустили выполнение. И вот этот набор команд начал выполняться до тех пор, пока не завершится выполнение всех команд, пока их выполнение кто-то не остановит специальной командой, либо пока в коде что-то не сломается, т.е. была ошибка, её не заметили, но проявилась она не сразу, а по мере выполнения. Такое поведение в компьютерах принято соответственно называть терминами «запустить программу», «прервать выполнение программы», «ошибка выполнения программы». Часто эти термины встречаются в англоязычном представлении:
run, exec, execute – запустить выполнение
break, abort, cancel, terminate, stop, exit, kill, die – прервать выполнение
run-time error – ошибка выполнения
Вообще, если строго говорить, то англоязычного очень много в программировании, если конечно вы не хотите изучать только язык 1С и ничего больше, но как правило, это маловероятно. Однако, английский язык вам специально изучать не нужно, просто в этом нет необходимости. Во время изучения какого-либо языка программирования, вам так или иначе нужно будет запоминать команды, что они делают, а их названия достаточно отождествлены с их смыслом. Например, команда input (пер.: ввод, подвод, подводимый) в языках программирования – это ввод данных, по смыслу подходит. Но если вы обладатель хороших знаний английского языка и встречаете команду print (пер.: печатать, напечатать, печатный), то чисто английский вам мало поможет, а может даже и навредит, т.к. на самом деле никуда на бумагу печатать ничего не будет, а это просто вывод на экран строки символов. Эта команда – история программирования, идёт с тех времен, когда на клавиатуре не писали, а печатали, а на экране синхронно выводился текст; говорили не «писать текст программы», а «печатать текст программы». Также лепту внес и древний язык бейсик, где команда, если не ошибаюсь PRINT#1, как раз выводила текст на тогда ещё матричный принтер. В общем, в современном мире программирования это вывод на экран строки текста, причём на большом количестве языков программирования. Ну привыкли все к этой команде, зачем менять. По этому нужен ли английский знать, ну так, нужен, но не в этом. Пригодиться язык может только для того, чтобы читать англоязычные форумы, где публикуют большое количество решений различных проблем, как то сделать, как это, а почему у меня не работает код, который написал, а что нужно написать, чтобы это заработало. Я часто бываю на этих форумах, но пользуюсь либо Гуглом для перевода, либо Яндексом))…Но уже сейчас замечаю, что что-то стал понимать и без переводчика, причём иногда даже если пишут фразу «Wt u know about…» (What you know about… – что вы думаете о…) или «I lkn 4…» (I looking for… – я ищу…). Опять таки, по многим языкам программирования есть огромное количество и русскоязычных форумов.
Что внутри компа?
Внутри любого компьютера (компа), есть следующие основные вещи:
1. Процессор, которым часто называют ящик на столе, который на самом деле системный блок. По факту процессор – это большая микросхема внутри системного блока, в которой и происходят все вычисления и координация действий всего компьютера.
2. Оперативная память, которая работает очень быстро, но способна хранить в себе данные только пока компьютер включен (синонимы – ОЗУ. RAM, DDR).
3. Постоянная память, которая работает намного медленнее оперативной памяти, но способна хранить информацию даже если всё выключено (жесткие диски – HDD, твердотельные диски – SSD, флешки)
4. Периферия – устройства соединяющие все внешние устройства (клавиатуры, мыши, принтеры, наушники, мониторы, очки виртуальной реальности, сетевые карты и т.п.) с процессором и оперативной памятью. Функционал периферии выполнен как правило на материнских платах (возможно этот термин вам уже встречался) и устройствах размещенные непосредственно на них. Однако есть и периферия, которая выполнена вне материнских плат, например, внешние жесткие диски, внешние аудио-карты для написания музыки, внешние устройства для захвата видео изображения и т.п.
С точки зрения программирования, всё что пишет программист – это написание функционала взаимодействия между этими устройствами. И вот тут есть важный момент, о котором чуть подробнее.
Работа компьютера с точки зрения программирования сводится к следующему принципу на протяжении многих десятков лет:
1. Ваша программа загружается из постоянной памяти в оперативную при помощи другой (системной) программы.
2. В оперативной памяти системная программа (которая загружала вашу) по ряду признаков определяет, где в вашей программе просто обычные данные, например обычные слова типа «Введите логин и пароль», которые вы часто видите на экране, и где в вашей программе код из набора команд, которые будут переданы процессору на выполнение.
3. Запускает выполнение кода программы.
4. Завершает выполнение кода программы
5. Стирает из оперативной памяти программу, освобождая драгоценное место (из постоянной не стирается)
Как из предыдущего можно понять, что пока программа находится в постоянной памяти на накопителе, это просто обычные данные, но как только они загружаются в оперативную память, часть из них становиться кодом выполнения, а часть продолжают оставаться в виде обычных данных. Чтобы такое происходило безотказно и компьютер всегда знал что у вас код, который нужно выполнять, а что есть просто данные типа фразы «Введите логин и пароль», нужно предварительно правильно подготовить вашу программу для запуска. Этот процесс называет компиляцией программы. Т.е. вы написали программу на языке программирования, но в таком виде процессор компьютера её не поймет. Теперь нужно её скомпилировать чтобы компилятор (программа, которая компилирует вашу программу) преобразовал её в тот вид, в котором процессор вашего компьютера её поймет и однозначно сможет определить где в ней находится код выполнения, а где простые данные. Как можно понять из вышеперечисленного, что в современном компьютере выполняется не одна какая-то программа, а одна программа передаёт выполнение другой, которая была загружена вами ранее или была загружена автоматически, и все внутри взаимодействует как большой электронный организм. Выполнение каждых программ регламентировано и происходит по разным правилам и с разными условиям. Например, вы по экрану водите мышкой и кликаете в браузере загрузить страницу, в этот момент происходит лавинный запуск сотен программ, одни грузят страницу из сети интернет, другие программы отображают её на экране, третьи проверяют не продолжаете ли вы двигать мышью по экрану, ещё одна продолжает отображать часы в углу экрана и ещё миллионы других действий. Всё это происходит в строгой последовательности со скоростью в десятки миллиардов раз за одну секунду, по этому кажется с виду, что всё запускается одновременно.
По этому знание и понимание этого очень важно для программирования. Сначала, когда вы включаете компьютер, запускается операционная система (Windows, Linux и т.п.), с точки зрения компьютера это тоже программа, которую писали программисты операционной системы. Потом, вы как программист, хотите написать свою первую программу. Для этого вам нужно загрузить среду разработки, это тоже некая программа, написанная другими программистами. Вы её загрузили, в ней написали свою программу, после этого запускаете в среде разработки компиляцию уже вашей программы. Теперь у вас есть готовый для запуска код, который вы уже можете запустить без среды разработки или передать друзьям знакомым, опубликовать в интернете и все, кто работает на такой же операционной системе как у вас, сможет выполнить написанную вами программу. Так и происходит весь этот процесс в общих чертах от программирования до конечного пользователя.
Как я уже ранее написал, в компьютере происходит взаимодействие различных программ. Их можно разделить на несколько типов с точки зрения уровня использования.
1. Операционная система. Это программа, которая является средством согласования различных пользовательских программ с конкретным вашим устройством. Например, вы наверно замечали, что в мире множество производителей мобильных устройств, ещё больше производителей микрочипов. Общего международного стандарта никакого нет, каждый производитель чипов как считает его функционал оптимальным, выгодным и конкуретноспособным, так и выпускает его. Получается так, что он определил какие команды будет этот процессор обрабатывать, а какие нет. При этом доминирующие операционные системы для мобильных устройств только две iOS и Android. Например, для Андроид зарегистрировано более 10 тысяч моделей различных телефонов на разных процессорах. И вот вы скачиваете на Samsung например приложение от Сбера, а ваш знакомый на Xiaomi скачивает это же приложение. И там и там оно работает. Как может быть такое чудо, ведь процессоры разные, команды делали их производители под то, как им удобно, а приложение выполняется и там и там. Это всё заслуга программистов операционных систем. Они написали специальные программы-драйверы для каждого процессора и каждого из 10 тысяч устройств. Эти драйверы являются частью операционных систем и являются промежуточным звеном к той же программе от Сбера, которые говорят, например «Слушай, Сбер, скажи пользователю, что я не могу оплатить покупку телефоном, т.к. в нем нет устройства NFC». А другой драйвер говорит, «Слушай, приложение камеры, предложи пользователю вариант включить свет на вспышке, т.к. уже темно в помещении». И это всё для каждого типа устройств писали программисты. Теперь понимаете, держа в руках телефон, какая титаническая работа десятков тысяч программистов была проделана, что бы каждый из нас мог пользоваться тем устройством, какое подходит под наш типаж, мировоззрение и комфорт? С точки зрения персональных компьютеров, всё примерно также как и в мобильных устройствах.
2. Драйвер устройства. Как уже упомянул, это программа часть операционной системы, но выделяет её в отдельную категорию лишь то, что поставляться драйвер устройства может отдельно от операционной системы. Такое раньше можно было часто встретить, например, при покупке новой мыши прилагался компакт диск с драйверами. В современных операционных системах большинство драйверов устройств уже есть изначально, но иногда их всё же нужно устанавливать. Правда, сейчас они чаще идут не на компакт-дисках, а находятся на официальных сайтах производителей оборудования. Например, купили видео карту, но операционная система поняла, что это видео карта и монитор показывает изображение, но производитель уже успел внести в её схему дополнения повышающее её производительность и возможности, но операционная система может об этом ещё не знать. По этому нужно этот драйвер скачать с официального сайта, установить и он станет частью операционной системы и откроет все возможности вашей видео карты.
3. Пользовательские программы. Это те программы, которые мы используем в повседневной жизни – текстовый редактор, калькулятор, бухгалтерские программы, компьютерные игры и т.п.
Первые два пункта – это стезя системных программистов. Здесь нужны глубокие знания в узкоспециализированной информации. Часто это информация скрыта и доступна только производителям оборудования или операционных систем. По этому стать программистом-системщиком (так их иногда называют) сидя за домашним компом попивая чаёк, крайне сложно, и всё потому, что документации найти сложно, а спрос на такие программы примерно равен нулю – никто не будет пользоваться вашими написанными драйверами, если есть драйвера производителя. Причины две – производитель лучше знает как должно правильно работать его устройство, информационная безопасность сильно страдает, так как часто драйвера обладают уровнем привилегий и прав больше обычных, и в случае неправильной работы могут навредить либо информации, находящейся на компьютере, либо самому компьютеру. Эта работа только для тех, кто работает непосредственно в организации по производству оборудования, либо у производителя операционных систем. Вопрос философский, куда пойдет программист-системщик, если уволится, ведь у него большие знания только в области одного типа/производителя оборудования? Сколько будет искать новую работу? Как на новом месте сможет адаптировать свои знания к новой структуре, может мгновенно, а может придётся с нуля приобретать новый опыт. Но, чаще всего, зарплаты там очень крутые, и увольняться обычно никого не тянет, кто-то наверно всю жизнь и работает на одной работе.
Что внутри программы?
Как я уже говорил ранее, программа – это набор команд. Программа выполняется сверху (сначала) вниз (в конец).
Все команды программы (любого языка программирования) делятся на несколько типов.
1. Присвоение значения переменной. Нужно чтобы потом удобно было работать с формулами – вы меняете значение только вначале, а дальше в формуле оно будет вычислено автоматически. Иначе нужно будет менять число далее во всех формулах, где встречается, и можно тут где-то случайно пропустить или ошибиться. Грубо говоря – это аналог математической переменной (кто в школе учил математику в 5 классе). Присвоение значения переменной принято называть инициализацией переменной. В некоторых языка программирования это обязательное условие компиляции, т.е. компилятор не позволяет как-то использовать переменную, пока вы дадите ей какое-то начальное значение.
a = 1
Как правило имя переменной может быть различным:
result = 0
Есть некоторые негласные правила имен переменных. Они выработаны в долгих поисках и чтении чужого когда, да и своего тоже, и придуманы не мной, а огромной командой программистов всех времен.
Во многих языках программирования переменные можно писать только латинскими буквами с цифрами и знаками _ (подчеркивание). Другие символы запрещены. Если это правило есть и в том языке, который вы будете изучать, то тогда сами переменные называйте английскими словами.
MoiResultat = 0; // НЕПРАВИЛЬНО – тут человек может взгляд сломать. Возми гугл, переведи и дай название переменной на английском, что ли…
MyResult = 0; // ПРАВИЛЬНО – название переменной латинскими буквами на английском языке
МойРезультат = 0; // ПРАВИЛЬНО – если язык программирования позволяет вводить кириллицей (например язык 1С), то так будет правильно
МайРизалт = 0; // НЕПРАВИЛЬНО – ты что бюргер что ли?
Иногда в название переменной закладывают сразу несколько слов, чтобы наделить её сразу смыслом. Если название переменной состоит из нескольких слов, то начинайте каждое слово с большой буквы.
myresultwhenigotinthemyfunctionfactorial = 1; // НЕПРАВИЛЬНО – Нормальный человек в здравом уме такое не прочитает…и не напишет…и представьте, что весь код такой и его сотни страниц…
MyResultWhenIGotInTheMyFunctionFactorial = 1; // ПРАВИЛЬНО – ну согласитесь, такое читать куда легче
myResultWhenIGotInTheMyFunctionFactorial = 1; // ПРАВИЛЬНО – первую букву иногда заглавной не делают, т.к. например в языке C и Java принято с заглавной буквы называть объекты, а с маленькой – их переменные.
ТаблицаВыгрузкиСальдоБухгалтерскихСчетовБезАналитикиСводноПоМесяцамКромеЗабалансовых = Неопределено; // ПРАВИЛЬНО – это 1С, товарищ, не хиханьки и не хаханьки! (это всё название переменной, без этого в 1С была бы засада)
В некоторых языках программировании при первой инициализации переменной необходимо обязательно указать тип данных, которые она будет хранить:
int a = 1; // Переменная a будет хранить только целые числа. Попытка запихнуть туда что-то другое, вызовет сначала недоумение компилятора и он попробует преобразовать это в целое число, например, 1.1922324 будет всё равно 1, либо просто начнет ругаться
string b = “Hello, world!”; // Норм! Так пойдёт! строку хранит переменная с типом строки
int a = “Hello, world!”; // СОВСЕМ НЕ НОРМ! – что за бодяга? как эта строка может быть целым числом??? С точки зрения компилятора – никак.
Разных типов может быть бесчисленное множество, так как программист может создавать свои собственные, но есть всё таки базовый набор простых типов, такие как:
Булево (bool) – тип переменной, которая может принять только одно из двух значений – истина или ложь
Целое число (byte, int, long, word, dword) – переменная может хранить только целые числа. Типов целого числа много, тут всё зависит от того до какого предельного значения вы хотите хранить целое число и нужен ли будет математический знак минуса (иногда необходимо хранить только положительные числа), это и определяет вариант.
Вещественное число (float, double) – числа, где нужно хранить дробную часть. Иногда их называют числа с плавающей точкой или плавающей запятой (оттуда и название float). Также их несколько и определяют точность дробной части.
Символ (char) – хранит символ
Строка (string) – хранит множество символов. В мире программирования постоянно происходят метания что при случае выбрать массив char или переменную string (см.далее массивы). Эти метания в основном связаны со спецификой работы каждого типа и функциональными особенностями языка, но по здравому смыслу это одно и тоже.
Переменная может быть массивом (о чем только что писал):
int p[100];
Это значит, что будет создано 100 переменных p, но доступ каждой из них будет по индексу, т.е. p[0], p[1] и т.д. Это удобно, когда нужно выполнить действия сразу над множеством значений одной смысловой группы, например, вы производили 10 замеров температуры на кухне до и после приготовления жаркого, и у вас есть 10 значений. Но вам нужно среднее, чтобы понять превышало ли это среднюю норму домашнего труда или нет. Можно конечно задать так:
a = 23;
b = 25;
c = 27;
d = 28;
….
j = 24;
и потом посчитать по формуле:
Tc = (a + b + c +…+ j) / 10;
а можно сделать так:
int temp[10];
temp [0] = 23;
temp [1] = 25;
temp [2] = 27;
temp [3] = 28;
…
temp [9] = 24;
Tc = 0; // Так надо, мы не начали ещё считать температуру, значение полинома равно нулю
for (i = 0; i < 10; i++) { // Перебирает от 0 до 9 значения i, а потом использует их как индексы массива для расчета среднего
Tc += temp [i] ;
}
Tc /= 10; // Взять из Tc значение и поделить на 10, а потом запихнуть обратно в Tc
Когда речь идет о сотнях или миллионах чисел, то массив – это единственное решение. Лично я, если чего-то такого больше двух, то как правило делаю массив. Процесс выбора правильного алгоритма, в каком случае взять массив, а в каком создать пару отдельных переменных, как назвать их чтобы потом было понятно, называется творчеством, по этому кто говорит, что программирование – это конвейерная рутинная работа – неправ!
2. Выражение. Иными словами, это формула с числами, переменными или иными величинами.
b = a+2
или
с = sin(alfa)
3. Условие. Когда при соблюдении какого-то условия нужно выполнить один код, а в ином случае его не выполнять. Например, для синтаксиса языка типа Си, это выглядит так
If (b == 2) {
// Что-то выполнить здесь, если вдруг окажется, что благодаря каким-то действиям компьютера это значение станет равным 2, то выполнить нужно код заключенный в эти фигурные скобки, в ином случае просто проигнорировать этот код и перейти дальше
}
Для языка 1С тоже самое:
Если Б = 2 Тогда
// Что-то тут
КонецЕсли;
Для Бейсика:
if b = 2 then
// ???
end
4. Циклы. Чтобы не быть как в анекдоте про нового русского, когда он летит в самолете, а стюардесса объявляет «Наш самолет летит в Баден-Баден», новый русский её останавливает и говорит «Слыш, тут чё лохи летят, зачем Баден два раза повторять?». Так вот чтобы не быть лохом, в программировании придумали циклы, т.е. конструкцию, которая позволяет выполнять одинаковую часть кода несколько раз.
Если делать неправильно, новый русский лохом бы назвал:
print(‘Мы летим в’);
print(‘Баден’);
print(‘Баден’);
А так правильно, новый русский бы оценил:
print(‘Мы летим в’);
for( i = 1; i < 3; i = i+1) { // Перебирать от 1 пока i будет меньше 3, т.е. только значения 1 и 2
print(‘Баден’);
}
Но как бы не делали, в результате на экране будет всё равно одно и то же:
Мы летим в
Баден
Баден
Всё как в анекдоте)))…ну, или не летим…))
5. Создание функций. Иногда они называются методами, иногда процедурами возвращающими значение, иногда подпрограммами, всё зависит от конкретного языка программирования. Это конструкции, которые позволяют делать что-то, что после некоторых манипуляций и алгоритмов будет возвращать результат какого-то выражения.
a = sin(alfa); // это стандартная функция вычисления синуса
function mySin(alfa) {
// Тут, если владеете математикой, раскладываете расчет синуса в ряд Тейлора-Маклорена, и пишите код, который будет вычислять его по вашему алгоритму. Например, если вам нужна бОльшая точность, чем вычисляет это стандартная функция
}
a = mySin(alfa); // А теперь можно наслаждаться результатом
6. Класс. Современные языки позволяют делать иерархию методов (см.п.5), когда несколько методов и/или переменных объединяются по смыслу в один объект – класс. Например, вы делаете приложение чем кормить ваших питомцев. Вам нужно по каждому из них хранить информацию, мол как зовут, что хавает, когда кормил последний раз, где нас***, да вообще как он чувствует себя после этого. Мы делаем класс и называем его ёмким словом «Питомец» (Pet)
class Pet {
string name = “???”
string type = “???”
string eat = “???”
function ThrowASlipperAtItBecauseItMadeAMess() {
// Тут какой-то код
}
function GiveCookies () {
// Тут какой-то код
}
}
Пока мы объявили только этот класс как иерархию, но чтобы каждого нашего питомца отразить нужно будет создать на каждого из них экземпляр этого питомца.
Pet pet1 = new Pet();
pet1.name = ‘Петроний’;
pet1.type = ‘Кот’;
pet1.eat = ‘Захавал мою сметану – не поплохело’;
pet1. ThrowASlipperAtItBecauseItMadeAMess(); // Выполнить код, запускающий в него тапок
Pet pet2 = new Pet();
pet2.name = ‘Барбос;
pet2.type = ‘Пёс’;
pet2.eat = ‘Принёс назад тапок для запуска его в кота, дал печеньку’;
pet2. GiveCookies (); // Этот код даёт питомцу печеньку
В класса есть такая штука как расширение одного класс другим. Например, для кота Петрония и пса Барбоса есть общие переменные, такие как имя, тип и еда, но вот давать печеньки коту глупо, а пулять тапком в собаку не безопасно. Т.е. для пса выполнить метод ThrowASlipperAtItBecauseItMadeAMess() (переводится как «запустить тапком, так как съел сметану») можно только в шаговой недоступности. По этому эти методы по идее должны быть уникальными для каждого типа. Это можно делать так:
class Pet() {
string name = “???”
string type = “???”
string eat = “???”
}
class PetCat() extends Pet {
function ThrowASlipperAtItBecauseItMadeAMess() {
// Тут какой-то код
}
}
class PetDog() extends Pet {
function GiveCookies () {
// Тут какой-то код
}
}
Объявление их тоже будет немного по другому:
PetCat pet1 = new PetCat();
pet1.name = ‘Петроний’;
pet1.type = ‘Кот’;
pet1.eat = ‘Захавал мою сметану – не поплохело’;
pet1. ThrowASlipperAtItBecauseItMadeAMess();
PetDog pet2 = new PetDog();
pet2.name = ‘Барбос;
pet2.type = ‘Пёс’;
pet2.eat = ‘Принёс назад тапок для запуска его в кота, дать печеньку’;
pet2. GiveCookies (); // Этот код даёт питомцу печеньку
Но никто не мешает делать, конечно, и так:
Pet pet1 = new PetCat(); // Всё внимание на тип вначале! Найдите отличия.
Pet pet2 = new PetDog(); // pet2 тоже с тем же типом, хотя создаётся экземпляр другого объекта (уже расширенного)
Но тогда перед тем как вызвать функцию, нужно сначала убедиться в типе этого объекта, т.к тип Pet ничего не знает и не ведает о том, что его где-то кто-то стал расширять.
Теперь уже не получится запульнуть в пса тапком и дать коту печеньку, т.е. например, так не выйдет – pet1. GiveCookies (); – этот метод теперь только для объекта PetDog(), компилятор скажет, что у этого объекта нет такого метода.
Как вы заметили, переменные объявляются только один раз в родительском классе (классе, функционал которого мы расширяем).
Этот способ позволяет делать библиотеки кода, когда вы компилируете свой класс, хотите поделиться им с кем-то, но не хотите чтобы кто-то узнал по какой формуле будет лететь тапок, и из какой химической гадости будут сделаны даваемые псу печеньки. Так вот, вы компилируете класс, создаете библиотеку, но позволяете другим программистам расширять ваш класс своими функциями, например общую для них – погладить по голове, или индивидуальные – почесать за ухом, дать ещё сметаны))). И если они сочтут, что ваш тапок летит в кота недостаточно быстро, то могут написать даже свой аналог функции ThrowASlipperAtItBecauseItMadeAMess(). Их компилятор увидит, что такая функция есть в вашей библиотеке, программист её расширяет, но у него тоже есть такая же функция, тут его компилятор и принимает решение, что код этого программиста всё-таки важнее вашего и даст ему расширить класс своим методом на замену.
7. Комментарии. Это те части кода, которые просто нужны чтобы программист сделал какие-то заметки для себя или других программистов, которые могут работать с этим кодом. Компилятор будет их полностью игнорировать.
Философия “Hello World!”
Когда-то в далёком эээ…уже не помню каком году, мы с одноклассниками сидели на табуретках с электрогитарами в руках и спорили нужно ли для хорошей игры учить пассажи известных музыкантов, таких как Джо Сатриани или Ван Халена. Мне говорили обязательно нужно, иначе не будешь знать основ и не сможешь нормально играть, а я говорил, что если я буду учить других, то мне сложно будет придумать своё, а в музыке это означает потерять индивидуальность. И как показала жизнь, у каждого была тогда своя правда. В программировании так же. Здесь нужно всего в меру, меньше неё будет недостаточно для написания рационального и лаконичного кода, а если будет слишком много – разрушит элементы творчества, ты просто превращаешься в великого комбинатора – взял там кусок кода, взял тут готовый метод…хотя, это тоже в некотором роде творчество. Приведу пример. Некогда я писал много и для души на ассемблере. Часто приходилось обнулять 32-битный регистр, т.е. записывать в него значение ноль. Я делал это таким способом, кстати, строго по умной книжке:
MOV EAX, 0
Эта команда занимала, если не соврать, 5 байт в режиме 32 битного режима процессора по умолчанию. Но потом дизассемблируя чей-то код из игрухи типа «Принц оф Персия», я увидел интересную конструкцию:
XOR EAX, EAX
которая занимала уже только 1 байт. Результат тот же, но логическое действие совершенно не очевидное, эта команда не помещает ноль в регистр, она берёт то, что там уже есть и исключает само себя. Согласитесь, это красиво как любимая женщина (с мужской стороны, как для милых дам написать, я не знаю, что для вас сравнимо по красоте)) ). Тут то я и понял, насколько важно всё-таки иногда заглядывать на то, как делают другие, и о чём в книгах могут не написать.
При изучении нового языка программирования, уже так повелось, люди первым делом пишут вывод фразы «Hello, world!», ну или «Привет, мир!» (кому как удобнее). И вот какой в этом смысл:
1. Вы понимаете, что у вас работает среда разработки
2. Вы понимаете, что у вас правильно настроен и работает компилятор
3. Вы понимаете какой именно код заставил миллиарды транзисторов вашего устройства выстроить такую последовательность сигналов, что это привело к написании на вашем устройстве этой фразы, и на этом этапе всё, что вы делали правильно, и это работает…кстати, иногда пишут и такую фразу «It’s work!» (это работает).
Моя рекомендация – начинайте всегда изучать языки программирования с этой фразы. Она даёт дозу того самого волшебного пинка – психологически, если сразу что-то начинает работать, хотя ты только начал изучать, сильно бодрит, внушает чувство власти тебя над вычислительной системой, она выполняет команды, которые ты вводишь как верный пёс)), как любовь с первого взгляда.
Соблюдайте следующие принципы программирования
1. Пишите правильные комментарии
Это значит, что вы их должны писать тогда и только тогда, когда это действительно нужно или требуется, и не пишите их для всего подряд.
Не делайте избыточные комментарии:
a = 0; // Поместить в a ноль чтобы проверить как на него делить – ПРАВИЛЬНО
b = 1 / a; // Поделить 1 на a, которое содержит ноль – НЕПРАВИЛЬНО (избыточно), и так ясно, что здесь 1 делиться на a, которое содержит ноль, что тоже указано в предыдущем комментарии
Не делайте код совсем без комментариев. Часто бывает, что текущий проект нужно отложить на время. Потом, когда вы сможете к нему возвратиться, вам точно будет сложно понимать некоторые вещи, особенно если проект большой. Если вы ведете командную разработку, то это может быть иногда даже обязательным условием – уважайте время других программистов, напишите почему вы делаете этот алгоритм именно таким, хотя бы вначале, вкратце.
Пишите комментарии в строгом стиле, не используйте личные окончания глаголов:
a = 0; // Поместим в a ноль и проверим как на него делить – НЕПРАВИЛЬНО – вы может и помещаете, а лично Мы – нет.
a = 0; // Помещаю в a ноль чтобы проверить как на него делить – НЕПРАВИЛЬНО – ну и хорошо, помещай дальше что хочешь, я тут при чём? Мне что за тобой следить нужно? И давай уже решайся быстрее что туда помещать!
a = 0; // Помещаем в a ноль чтобы проверить как на него делить –
НЕПРАВИЛЬНО – я уже ответил про вас, мы не помещаем ничего никуда, тем более в перманентном процессе, да, это будет, но только один раз…и без вас
a = 0; // Помести в a ноль и проверь как на него делить –
НЕПРАВИЛЬНО – как ты груб с компом, фу!
a = 0; // Поместить в a ноль чтобы проверить как на него делить – ПРАВИЛЬНО – да, нужно поместить, а уж пометит ли он на самом деле и определяет что ты за программист и на каком железе работаешь)).
Кстати, в математике нельзя поделить число на ноль, но в компьютерных процессорах – можно. Результат будет «не число». Но большинство программ отрабатывают этот результат деления как ошибку «Деление на ноль», ну чтобы не вводить в заблуждение рядового пользователя)).
2. На каком бы языке вы не программировали, делайте код таким, чтобы он был наиболее удобно читаемым.
ЕслИ а = 1 ТОгДА ЧтоТоОБъЯвляюЗдесьПотомВыход = Истина; КонЕцЕсли; // НЕПРАВИЛЬНО – буквы скачут, всё условие в одну строку. Это всё равно что программиста, который будет этот код читать, обматерить в грубой форме
// ПРАВИЛЬНО – удобно читать код, код аккуратен.
Если а = 1 Тогда
ЧтоТоОбъявляюЗдесьПотомВыход = Истина;
КонецЕсли;
Например, я когда пишу, могу для удобства даже разделять смысловые методы пустой строкой, так читать удобнее и искать нужное гораздо быстрее, когда часами проводишь за компом…или перед компом…
Так пишу я:
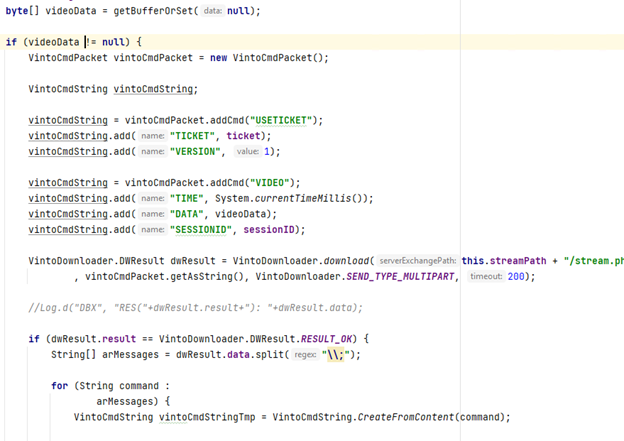
Хотя никто не запрещает писать так:

Но согласитесь, в первом варианте читать намного легче и при этом код не загромождается. Очень быстро визуально искать нужное.
3. Сам язык программирования (любой) выучить не сложно, имеется ввиду его синтаксис, потому что выучить все методы современного языка физически невозможно, их десятки тысяч, да и кому это нужно. Например, зачем вам глубоко погружаться в специфику программирования для работы с устройствами Bluetooth, если вы никогда не будете их программировать в обозримом будущем, а только по этим классам сотни методов. С другой стороны, знание только языка вряд ли сможет закрыть вопросы решения современных задач. Так или иначе нужно изучать смежные технологии. Например, если вы решили сделать программу, которая передаёт файл по сети в другую такую же программу, то вам как минимум нужно будет понимать как работает сеть, чтобы знать логику и порядок выполнения тех или иных команд, их значения. Например, невозможно это сделать в ряде случаев, если вы не знаете что такое IP адрес, доменное имя или что такое сокет, не знаете, что сокет нужно открывать, а после использования закрывать. Даже не знание простых вещей иногда приводит к неверной работе программы. Например, вы в своей программе выделяете место в оперативной памяти, и как это сделать вам даст изучение языка, но нужно ли потом принудительно освобождать память и в каких случаях это нужно делать принудительно, а в каких система сама разберется с этим лучше, чем кто либо, знание только языка программирования вам не даст. Там например будет просто описание функции free() – освобождает память, а зачем она это делает, а зачем вообще это нужно, ни одно описание языка программирования вам это не скажет. Многие описания предполагают принцип «Вы конкретно знаете что хотите сделать, но определенно не знаете как это сделать».
Итог
Теперь остается только хорошенько всё обдумать, выбрать нужный язык программирования и приступить к созданию своей первой программы.
Начало программирования вообще с нуля. Часть 2
Для любого программиста знание что такое биты и байты, что такое системы счисления, является обязательным даже в современном мире. И значимость этого не меньше, чем много лет назад.
Элементарной единицей информации является бит, который может принимать одно из двух состояний – истина и ложь. В электронных схемах истина выражается в виде напряжения 5 вольт, либо 3.3 вольта, либо ещё как-то больше нуля (всё зависит от параметров электронной схемы), а значение ложь в виде отсутствии напряжения. В цифровом виде истина представляется значением 1 (единица), а ложь значением 0 (ноль).
Биты принято объединять в группы. Элементарной группой является байт, который равен восьми битам. Почему именно 8 бит, а не 10 и не 100, станет понятно позже, а если не станет, то я расскажу.
Как мы обычно привыкли записывать число? Ну как? – Вот так:
123 – сто двадцать три
Но на самом деле, с точки зрения математики, это выглядит вот так:
123 = 1 * 100 + 2 * 10 + 3 * 1
где * (звездочка) – так обозначается знак умножения.
Т.е. цифры в своих разрядах, дают нам конечное число именно по такой формуле. Однако и это не полностью адекватная запись, по тому что ещё более правильно было записать так:
123 = 1 * 10 ^ 2 + 2 * 10 ^ 1 + 3 * 10 ^ 0
где ^ (галка) – степень числа
Вспоминаем математику, что любое число в степени ноль – это единица, и 10 ^ 0 – не исключение
Тут видим, что именно степень числа и определяет полностью разряд числа (за плюсом 1). Т.е. в школе учили нас, что справа стоит первый разряд числа, но в программировании это нулевой разряд. Заметьте, каждый разряд содержит основание 10, меняется только множитель и его степень, но степень зависит только от разряда. По этому наше число для наглядности выглядит так:
123 = ( 1 ) * 10 ^ 2 + ( 2 ) * 10 ^ 1 + ( 3 ) * 10 ^ 0
– наши цифры 1, 2 и 3 от числа 123 показаны в скобках, 10 – постоянный в каждом разряде, а степени 2, 1 и 0 – это просто номера разрядов числа (справа налево). Вот и всё – это наше число так выглядит. Теперь важный момент. За счет того, что везде основание стоит 10, эта наша система счисления, который мы пользуемся в повседневной жизни, называется десятичная; вот как раз по тому, что основание 10. Это означает, что цифры, которыми мы ведем счет (значения в скобках) могут быть только от 0 (нуля) до 9 (девять). Цифры 10 нет в нашей системе счисления, т.к. запись числа 10 уже не простая. 10 – это:
10 = 1 * 10 ^ 1 + 0 * 10 ^ 0
Вот по тому цифры 10 и нет в нашей десятичной системе счисления, потому что иначе бы запись стала не упрощённой.
Всё это хорошо, только для повседневной жизни, потому что мы к этому привыкли, нас с детства начинают учить считать до 10 (по числу пальцев на руках), но в мире информационных технологий хранение информации в десятичном представлении расточительно. Почему так – далее.
Как понимаете, если есть десятичное представление числа, то есть наверно и ещё какое либо. Что будет, если мы вместо 10 в основание поставим 2. Как будет выглядеть, например, число 6?
6 = 1 * 2 ^ 2 + 1 * 2
а теперь запишем по всем предыдущим правилам:
6 = ( 1 ) * 2^2 + ( 1 ) * 2^1 + ( 0 ) * 2^0
получается, что это число 110, но только в двоичной системе счисления, т.к. основание здесь 2, а не 10. Т.е. для записи используется только две цифры – ноль и один (по тому и система двоичная).
ВНИМАНИЕ! Число 110 в двоичной системе – это НЕ(!) сто десять(!!!),- это число один один ноль!
Чтобы как-то понимать, что это в двоичной системе, принято записывать это так:

Однако, в двоичной системе не всегда удобно записывать числа, особенно большие. Например, обычное для нас число 700120 (семьсот тысяч сто двадцать) в двоичной системе выглядит так:
10101010111011011000b
Ну, тут и без объяснения понятно, что сложно работать с числом в таком виде, и такая запись используется только в определенных случаях. По этому чаще числа представляются в другой системе счисления, в шестнадцатиричной. Т.е. системе, где счет цифр идёт от нуля до 15. Ну, подождите!- скажите вы. Что это за цифра такая 15, это число такое 15, а цифры такой нет; да и 14 такой цифры тоже нет, и вообще цифр больше 9 цивилизации не известно! Так то оно так, и вы в чём-то правы, но вы наверно не знали, что цивилизация уже придумала такие цифры, но только для программистов)). Откройте стандартный калькулятор в Windows и переключите его в режим “Программист”:
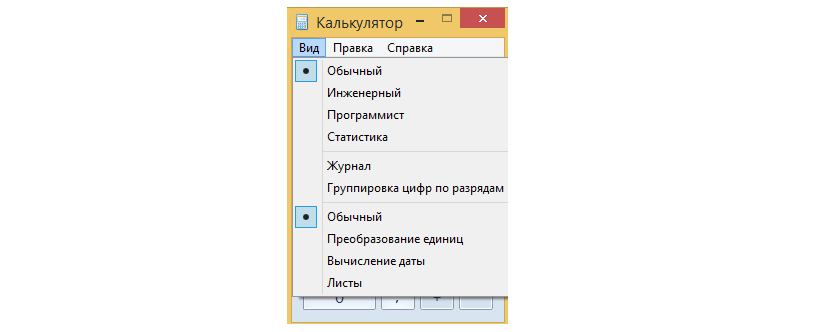
Получится так:
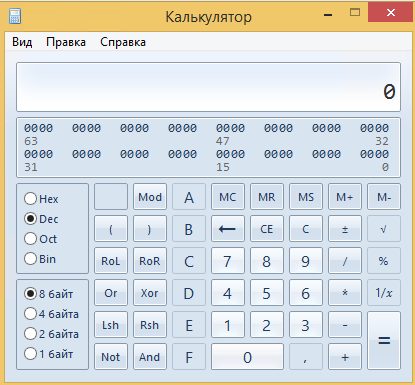
Введем число 700120:
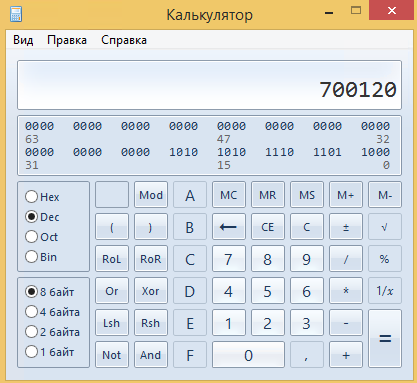
А теперь переключим режим представления числа на Hex (шестнадцатиричную систему счисления, от слова Hexadecimal):
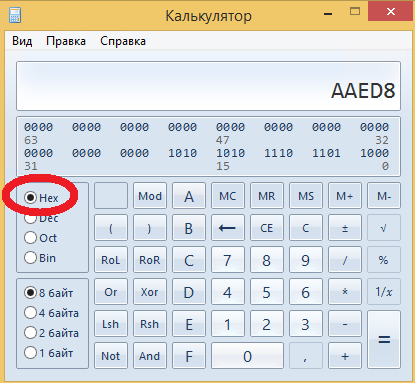
Вот так и выглядит это число. Правильные записи этого числа (понятные другим программистам) будут такие:

Часто шрифтом написать подстрочный текст 16 бывает невозможно, особенно в редакторах типа Блокнота, по этому предпочитают линейным текстом, т.е. AAED8hex, AAED8h (маленькими буквами признак системы счисления), но чаще всего выглядит так – 0xAAED8 (ноль икс перед числом).
Кто-то может догадался, что эти буквы означают, а кто-то нет. Ответ вот:
A – это цифра 10
B – это цифра 11
C – это цифра 12
D – это цифра 13
E – это цифра 14
F – это цифра 15
Получается, что наше число 700120 будет выглядеть при правильной записи так:
700120 = ( A ) * 16 ^ 4 + ( A ) * 16 ^ 3 + ( E ) * 16 ^ 2 + ( D ) * 16 ^ 1 + ( 8 ) * 16 ^ 0
Теперь возвращаемся к вопросу расточительности, запишем число 255 (двести пятьдесят пять) сразу в трех системах счисления:
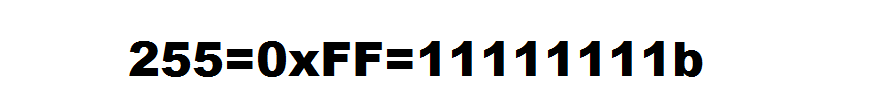
В десятичной системе число занимает три разряда (разряды 0, 1, 2), в шестнадцатиричной системе – два разряда, а в двоичной 8 разрядов. Наиболее компактная запись получилась как раз в шестнадцатиричной системе счисления.
Но погодите! Вы же внимательно читали этут статью с самого начала! Я как раз писал, что бит имеет только два состояния 1 или 0 (истина или ложь), а в двоичной системе как раз тоже используется только две цифры 0 и 1, так может быть биты записывать было бы удобно в двоичной системе? О да! Это так, для этого и используют двоичную систему счисления, как раз в тех случаях, когда и нужно работать с какими-то данными именно в битовом представлении, т.е. когда сама информация важна с точки зрения отдельных битов, а числа целиком. Но что с нашим числом 255? Если вы были ещё более внимательны, то увидите, что число 255 – это как раз максимальное число, которое можно представить восемью битами, т.е. одним байтом. Мало того – это максимальное число которое можно представить двумя разрядами шестнадцатиричного числа, а именно – FF. Именно по этому, когда речь идет о каких-то хранящихся внутри системы данных, которые иногда называют бинарными данными, их принято представлять либо в шестнадцатиричном исполнении двумя разрядами, либо в двоичной системе, если важна именно битовая составляющая. Так наше число 700120 (0xAAED8) в виде бинарных данных по два разряда в каждом выглядело бы так:
0A AE D8
Заметьте, к левому разряду пришлось слева подставить ноль, который как вы понимаете, никак не влияет на результат ( 0xAAED8 = 0x0AAED8 ), а сами байты разделить пробелом для лучшего визуального восприятия. Теперь, глядя на эту запись стало понятно, что для хранения числа 700120 компьютеру потребуется выделить три байта памяти (как понимаете, все числа от нуля до 700120 в три байта тоже запихнуть получится). Теперь наоборот, а интересно какое максимальное число можно поместить в три байта? Конечно же это число FF FF FF, а “по-нашему” – 16 777 215. Т.е. любое число от 0 до 16777215 включительно можно сохранить в компьютере используя не более трех байт.
Вот для чего по прежнему используются системы счисления в современном мире – чтобы иметь полное представление сколько памяти нужно выделить для хранения той или иной информации, чтобы это было и не расточительно и перекрывало все необходимые требования (и забегая вперед – не только для этого). Вы скажите может быть,- Да что такое один байт в современном мире, его никто не будет считать?! А вот и нет. Все мы наверно часто работаем в сети интернет, читаем тексты, смотрим картинки, видео. Каждая картинка или один кадр видео – это набор пикселов, каждый представленный чаще всего тремя байтами – по одному байту на каждую компоненту цвета (красный, зеленый, синий). Если вы вместо трех байт выделите четыре, то это увеличит объём необходимых накопителей для хранения картинок и видео на 1/3, что примерно также увеличит и стоимость и обслуживание. Мало того, любое расточительное использование памяти, не вызовет уважение у ваших коллег, если они это заметят, т.к. каждый понимает, что в программировании расточительство ресурсов – это признак дурного тона, непрофессионализм, безалаберность, качества несолидного человека, разгельдяя. Делайте хороший код, старайтесь беречь ресурсы, демонстрируйте этим свой профессионализм!
Начало программирования вообще с нуля. Часть 3. Бинарные данные.
В прошлой части мы начали говорить о бинарных данных. Давайте немного углубимся в этот вопрос. Если рассуждать по честному, то вся информация в компьютере – это бинарные данные. Отличается только их смысл и представление. Давайте откроем некий файл для просмотра и вроде как он содержит обычный текст:

Рис.1
Теперь немного изменим представление этого же файла:
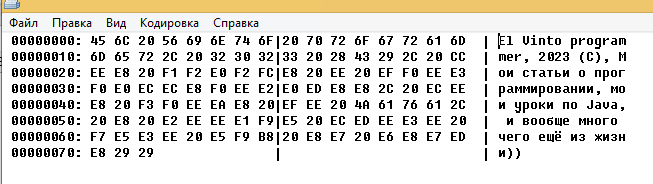
Рис.2
А теперь ещё поменяем представление на другое:
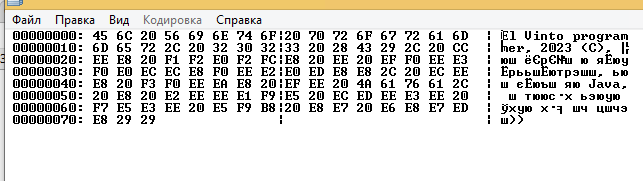
Рис.3
В средней части, как вы возможно уже читали предыдущую часть из серии “Начало программирования вообще с нуля” и догадались, хранится байтовое значение представленных с права символов. Т.е. бинарные данные. Весь представленный текст – это 115 байт информации.
Самая левая часть – это колонка с адресом, далее идут две средние колонки двоичных данных по 8 байт (всего в строке 16 байт), а справа их представление. Как можно заметить, какое бы представление не было, бинарные данные одни и те же. И это не удивительно, ведь они и есть истинная исходная информация. То, как мы хотим её видеть, в виде чисел шестнадцатиричной системы, или текстом в разных видах, вопрос другой, на самом деле данные одни и те же.
Теперь вопрос касаемый представления. Давайте посмотрим на все это немного подробнее. Заметьте, везде пробел представлен числом 20h, цифра 2 в годе 2023, представлена числом 32h. Ещё один момент, на который нужно обратить внимание – это то, что в представлении на рис.1 и рис.2 весь английский текст и цифры выглядят одинаково, а весь русский текст по разному. Дело в том, что тут есть одно правило. Все символы латинского алфавита, цифры, знаки препинания, пробел и ещё некоторый набор символов являются представлением байта со значением меньшим 128, т.е. байты 00-7Fh, и за каждым значением всегда закреплен определенный символ. Диапазон 80-FFh – это пользовательские символы представляемые определенной кодировкой (но есть небольшое исключение). Казалось бы, зачем было так делать?
Когда-то давным давно, когда каждый день вызывал перерождение компьютерной идеологии, большая часть информации вносилась на английском языке. Однако, в процессе интеграции компьютеров по всему миру, его стали использовать для отображения текстов на русском, немецком, французском, японском и т.д. языках. Сначала, до появления WIndows, за то, в какой национальной среде какие 2(!) языка использовать (английский и ещё какой) отвечали настройки операционной системы. Затем, когда стали вдруг появляться тексты сразу на нескольких языках (на одном рабочем месте), стали использовать отдельные символы. Ну, например, 00-7Fh – это всегда английские, 80-FFh – это как бы русские, но есть ещё несколько символов из испанского, такие, например, как ò (ударная о) или è (ударная е), также туда были добавлены некоторые буквы норвежского языка, например, å, и т.п. В общем, с горем по полам, как-то писались тексты. Проблемно стало, когда в языки стали включать иероглифы, которых, как мы понимаем, несколько больше, чем все алфавиты романской группы и кириллицы. Нужно было что-то менять. Стали придумываться разные кодировки, но беда была в том, что либо туда что-то не попадало, как кодировка ASCII или ANSI, либо туда попадало всё, но текст стал занимать место на дисках в несколько раз больше. В то время дисковые накопители обладали размером в сотни тысяч раз меньшим, по этому такое расточительное хранение текста считалось недопустимым. Со временем диски стали лавинно увеличиваться в размерах, а программисты искали методы для более эффективного хранения текстовой информации. На стыке одного и другого и произошли радикальные изменения. Но история об этом хранится, и теперь от старых кодировок быстро не отделаться, т.к. много текста хранится в них. Также есть старые операционные системы или микрокомпьютеры, где не нужно хранить текст, например, на китайском, а достаточно хранить на английском. Например, моя посудомоечная машина Ariston может вообще показывать только цифры и буквы P и E, зачем управляющей ей операционной системе хранить текст в современной кодировке? Кстати и стиралка тоже лексиконом не блещет)). Наиболее же перспективной кодировкой на 2023 год является кодировка UTF-8, она позволяет хранить текст одновременно на всех алфавитах (в т.ч. и иероглифы), даже например такие как Ѭ, Ѧ. Это всё потому, что под каждый символ национального языка, выделяется памяти больше одного байта. Также на правильное представление влияет не только в какой кодировке хранится текст, но и какая кодовая таблица используется. Т.е. кодировка из текстовой строки получает набор кодов символов, вторая таблица коды символов ассоциирует с определенным знаком/символом/буквой/иероглифом. Кодовая таблица сейчас используется unicode.
По этому, говоря о данных находящихся в компьютерах, принято иногда характеризовать о каких данных идет речь, о бинарных или нет. В итоге, например, нельзя просто сказать “Пришли мне бинарные данные надписи Привет, мир!”, потому что она содержит текст на национальном языке и не понятно в какой кодировке тебе их прислать. В кодировке ASCII это будут вот такие бинарные данные:

В кодировке UTF-8 это будут уже такие бинарные данные:

Как видите строка UTF-8 занимает куда больше места, хотя это тот же самый текст “Привет мир”. Однако, попробуем закодировать ещё и надпись “Hello world”, в ASCII это будет:

а в UTF-8:

Видно, что последовательность бинарных данных для текста “Hello world” одинаковая 48 65 6C 6C 6F 20 77 6F 72 6C 64. Каждому байту соответствует символ, что не скажешь о русских буквах. Получается, что если текст содержит только латинские символы, знаки препинания, цифры (это все символы с кодом меньшим 80h), то количество байт, требуемых для хранения такого текста равно количеству символов. Если текст содержит символы на национальных языках, то количество байт для хранения требуется больше.
С хранением строк должно быть немного понятно, а что с хранением в компьютере чисел. Дело в том, что как мы уже знаем, в одном байте можно хранить только целые числа от нуля до 255, а в двух байтах (по законам математики) от нуля до 256*256-1 = 65536, в 4-х байтах от нуля до 256*256*256*256-1=4294967296 и т.д.
Но мы знаем, что числа бывают отрицательными, как быть с этим? Здесь мы должны сначала определиться сколько мы будем выделять байт под число. После этого нам придётся пожертвовать одним (старшим) битом числа для определения знака. Если этот бит будет равен нулю, то это будет положительное число, а если 1, то отрицательное. Т.е. например, если нам нужно выделить переменную, которая будет хранить целое положительное число гарантированно не превышающее 255, то нам достаточно одного байта. Если же при этом число может быть отрицательным, то тогда уже без 1 старшего бита, т.е. только число не более 127 и не менее минус 127. Это может, например, использоваться тогда, когда вам нужно хранить проценты от 0 до 100% или от -100% до +100%, да мало ли ещё для чего может быть использован такой небольшой интервал. Однако, что с бинарными данными числа? Рассмотрим, например, бинарный байт E5h. Какое число в нём хранится, минус 27 (-27) или плюс 229 (+229)? Ведь с точки зрения бинарных данных и то и это будет E5h. Здесь тоже, как и со строкой, необходимо знать заранее, что это за бинарные данные. Если байт хранит целое положительное число, то тогда это 229, а если целое знаковое число, то уже -27. Это всё потому, что у E5h ( равен 1110 0101b ) старший бит единица и для знаковых чисел этот бит интерпретируется как признак минуса, а для беззнаковых чисел он просто ещё один старший бит числа.
Однако, я уже сказал, что целые числа могут храниться не только в байтах, но и в словах (это термин обозначающий 2 байта подряд – WORD), двойных словах (4 байта – DWORD) и т.д. Давайте посмотрим на это же число 229, если хранится в 2-х байтах. Бинарные данные тогда для него будут такими:
00 E5
Но оно и понятно – вот они два байта, старший байт нули, т.к. для этого числа и одного байта хватает, а младший байт всё тот же E5h. Однако, при хранении этого числа в двух байтах, старший бит (15-й по счёту) никогда не будет единицей – старший же байт целиком ноль. По этому становится не важным, перед нами 2 байтовое число знаковое или беззнаковое, оно всегда будет представлено как +229. Чтобы оно стало вдруг минус 27, бинарные данные должны быть такими:
FF E5
Но опять-таки это правило будет работать только для чисел не превышающих 2^15 (2 байта это 16 бит, но без знакового бита – 15). Как только число будет больше, уже опять нужно заранее знать знаковое там целое число или беззнаковое.
Из этого примера должно стать ясно, что в компьютере бинарные данные – это просто набор байт. То, чем это является на самом деле, текст, картинка, видео, файл экселя, файлы каких-то программ, решать пользователю, системе и прикладным программам, ну и конечно же программисту; они должны знать какой смысл этих бинарных данных, с которыми они работают.
В связи с этим во многих языках программирования чтобы задать переменную необходимо явно указать, что это за переменная – строка, байт, целое число под которое выделено 2 байта, 4 байта или даже 8 байт, а может это вообще вещественно число (число с дробной частью). Также, если это целое число, нужно указать есть ли у него знак или его нет. Исключение составляют вещественных числа – для них признак знака не указывается, т.к. физически сложно представить задачи, где нужно хранить дробное только положительное число. В связи с этим есть примерный ориентир при объявлении переменных:
byte a; // выделяется 1 байт, хранит целое число беззнаковое число
short int b; // выделяется 2 байта, хранит знаковое число
unsigned int c; // выделяется 2 байта, хранит беззнаковое число
int d; // выделяется 4 байта, хранит знаковое число
unsigned int e; // выделяется 4 байта, хранит знаковое число
long f; // выделяется 8 байт, хранит знаковое число
unsigned long g; // выделяется 8 байт, хранит беззнаковое число
long long h; // выделяется 16 байт,…
float i; // выделяется 4 байта, хранит вещественное число
double j; // выделяется 8 байт, хранит вещественное число
Хотя некоторые современные микропроцессоры поддерживают знаковый байт, компиляторы делать этого не позволяют, т.к. этот формат считается устаревшим и слишком специфическим.
Иногда для старых процессоров или процессоров для микроустройств, концепция немного изменена, особенно если процессор 32-битный или 16-битный. Там под int выделяться может только 2 байта, а под long – 4. Но обычно такая нестыковка проблем не вызывает, т.к. любой современный компилятор при необходимости может сообщить сколько же он будет выделять памяти под ту или иную переменную.
Со строками не так всё однозначно. Если программист захочет узнать сколько же байт памяти занимает у него в строке, то пока он не выгрузит эту строку в бинарные данные, не сможет этого подсчитать. Опять-таки за счет того, что строка может быть в разной кодировке – нужно сначала раскодировать строку в бинарные данные, а потом уже считать.
Существует ещё миллионы различных представлений бинарных данных, кроме строк, тут всё зависит только от того, какой в них был первоначальный смысл. Например, бинарные данные:
65 65 65 65
Что это? Это строка из 4-х символов “eeee”, это беззнаковое число int равное 1701143909, а может это программист тут хранит картинку 2 на 2 точки и 65h – это оттенок серого каждой точки? А может это часть сэмпла какого-то музыкального произведения, а может это исполняемый код процессора? Если заранее это не известно, для обычного читателя этих байт – это просто бинарные данные.
Начало программирования вообще с нуля. Часть 4. Логика.
...Люба повернулась к нему и произнесла
– Сергей, так ты сказал мне неправду?
– Нет, я сказал тебе ложь.- После этих слов она пренебрежительно отмерила его взглядом и не произнося ни слова, ушла прочь.
Однако в компьютерах такое вряд ли могло быть, ведь там есть только два состояния – истина или ложь, и в теории никогда не бывает неправды, сейчас я это объясню.
Ранее мы уже рассмотрели этот вариант, что бит со значением 0 (ноль) – это ложь, а бит со значением 1 – это истина.
Кстати, чтобы не путать букву “О” и цифру “0” (ноль), ноль когда-то давно выглядел вот так Ø (перечеркнутый ноль) и это действительно было удобно, ведь это два разных символа, и иногда шрифт такой, что не сложно их спутать. Особенно, когда речь идёт о так называемых Captcha – кодах из букв и цифр, которые нужно пользователю ввести, чтобы “подтвердить”, что он человек. Мне кажется, этот символ незаслуженно пропал из обихода. Сейчас он используется крайне редко.
Итак, истина или ложь. Например, я хочу изложить состояние погоды вчера и сегодня и говорю,- вчера шёл дождь, а сегодня дождь не идёт. Значит получается, что вчера наличие дождя – это истина, а сегодня наличие дождя – это ложь. Вроде тут всё должно быть понятно, мы одним битом можем описать был дождь или его не было, но это только если…я не соврал. Тогда возникает третье состояние – неопределенности, т.е. дождь-то на самом деле был, но я сказал, что его не было, а как моему собеседнику считать, всё-таки был дождь или нет? У людей такое происходит сплошь и рядом, а вот в вычислительных системах крайне редко. Человек подвержен воле, а компьютер – электромагнитным всплескам, и то и другое влияет на результат, но если в компьютерах это предусмотрели и сделали контроль ошибок и автоматическое их исправление, то у людей, скорее всего такого контроля нет. По этому, хоть вопрос и сложный, мы будем исходить из теории того, что в компьютерах есть только два состояния и никогда не бывает никакого другого.
Теперь рассмотрим обычную фразу “Я пойду на улицу гулять, только если не будет дождя, ну или хотя бы будет тепло”. С точки зрения компьютерной логики эта фраза бы выглядела так:
ЖеланиеИдтиГулять = НЕ Дождь ИЛИ Тепло
Тут есть вопросы по этой формуле? Со всем согласны и всё поняли? Если не так – пишите комменты разберём, это основы, которые нужно понимать с самого начала. В этой формуле есть два логических действия:
- “НЕ” – знак отрицания, отрицание переменной стоящей после него, т.е. если переменная была равна 0, то становится 1, и наоборот. Иногда называется инверсией аргумента, а операция – инвертированием.
- “ИЛИ” – называется логическое сложение. Результат истина, если хотя бы одна из переменных стоящих слева или справа от него равна истине
Так, а можно ли записать это желание идти гулять как-то по другому? Конечно можно, ведь я мог сказать и по другому – Я пойду на улицу гулять, только если не будет дождя или будет не холодно”. Согласитесь, общий смысл совершенно такой же. Как такая фраза будет записано логической формулой?
ЖеланиеИдтиГулять = НЕ Дождь ИЛИ НЕ Холодно
Мы заменили наличие теплой погоды с истины на ложь, но поставили перед этим оператор “НЕ”, и вернули смысл этой части выражения. А можно ли ещё как-то сказать фразу с этим же смыслом? Да, можно и по другому – Я не пойду гулять, если будет дождь и одновременно будет холодно. Смотрите, я сохранил общий смысл фразы, но аргументы формулы изменились полностью:
НежеланиеИдтиГулять = Дождь И Холодно
Однако, мы не знаем, что такой за результат “Нежелание”, у нас должно быть желание, поэтому перефразируем – Я пойду гулять, только если не будет одновременно идти дождь и на улице холодно, т.е. фактически так:
ЖеланиеИдтиГулять = НЕ (Дождь И Холодно)
Мы просто переставили НЕ из левой части в правую, так можно делать даже и в математике:
-A = B
=>
A = -B
Не будем отвлекаться, в этой нашей формуле мы использовали новый оператор “И”:
- “И” – называется логическое умножение. Результат истина только если оба аргумента (слева и справа) будут истина, в ином случае значение будет ложь.
Из этих трех логических операторов И, ИЛИ, НЕ состоит вся компьютерная логика. В зарубежной литературе они называются аналогично – AND, OR, NOT.
В различных языках программирования эти действия используются постоянно, на них построены все результаты сравнения и условия. Например, в языке Си эти операторы записываются специальными знаками &, |, !, например:
C = A & B;
D = A | B;
E = !A;
, а в языке 1С – прямо по-русски:
ПрибалятьКСуммеНашихОстатков = НЕ СчетЗабалансовый И ЭтоУчетТоваров;
Мы помним из младших классов математики, что у вычислительных операций есть приоритет. Сначала производятся все умножения и деления, а затем вычитания и сложения, но весь этот приоритет выполняется с учетом скобок (если они есть). В логических операциях как-то примерно так, но немного по другому. Скобки имеют тот же смысл, что и в математики. Операции в скобках выполняются первыми (с учетом приоритета каждой операции внутри самих скобок). Самый высокий приоритет у операции отрицания, все операции “НЕ” выполняются в первую очередь (опять-таки с учетом скобок). Затем выполняются операции логического умножения, а уже после них логического сложения. Чтобы понять объясню “на пальцах”. Есть формула:
Результат = НЕ (Параметр2 И Параметр3 ИЛИ НЕ Параметр4) И Параметр5
Первым делом будет выполнена инверсия находящаяся внутри скобок:
НЕ Параметр4
Затем будет выполнено логическое умножение:
Параметр2 И Параметр3
После этого будет выполнено ИЛИ между ними. Затем будет инверсия находящегося этого промежуточного результата в скобках:
НЕ (…)
И лишь после этого инвертированный промежуточный результат будет логически умножен на Параметр5 и получен итоговый Результат.
В логических операциях есть метод упрощения, который может существенно улучшать читаемость логической формулы, особенно когда условий в ней очень много, например:
ЖеланиеИдтиГулять = (НЕ Дождь ИЛИ НЕ Холодно) ИЛИ НЕ (НЕ ДеньПослеЗарплаты ИЛИ НЕ ЭтоПятница)
Ну так когда же я захочу идти гулять при такой формуле??? Обязательно ли новое условие, что это должен быть день после зарплаты и это должна быть пятница, или я пойду в такие дни гулять при любой погоде, или нужно соблюдение всех перечисленных условий? Для этого нужно упростить хотя бы выражение чтобы не “ломать голову” сложными преобразованиями. Для этого нужно знать три простых метода преобразования:
Метод1: НЕ НЕ Параметр1 = Параметр1
Метод2: Параметр1 И Параметр2 = НЕ (НЕ Параметр1 ИЛИ НЕ Параметр2)
Метод3: Параметр1 ИЛИ Параметр2 = НЕ (НЕ Параметр1 И НЕ Параметр2)
Тогда можем преобразовать левую часть сначала по методу 2, а следом по методу 1:
(НЕ Дождь ИЛИ НЕ Холодно) = НЕ (Дождь И Холодно), т.е. левая часть говорит, что результат истина, если нет одновременно дождя и на улице холодно, т.е. если хотя бы нет дождя или хотя бы не холодно, то результат этой части истина.
Теперь вторая часть тоже по тем же методам:
НЕ (НЕ ДеньПослеЗарплаты ИЛИ НЕ ЭтоПятница) = (ДеньПослеЗарплаты И ЭтоПятница)
В результате получается:
ЖеланиеИдтиГулять = НЕ (Дождь И Холодно) ИЛИ (ДеньПослеЗарплаты И ЭтоПятница)
По-русски это будет звучать так: У меня будет пойти желание гулять, только если нет на улице одновременно дождя и холода независимо от дня зарплаты и дня недели, но могу и пойти гулять если это день после зарплаты и одновременно этот день выпадет на пятницу независимо от погоды. В ином случае желания гулять не возникнет. Операция “ИЛИ” между левой и правой частью как раз и делает языковое выражение словами “независимо” или словами “хотя бы”, т.е. раньше я говорил, что “ИЛИ” – это когда истина хотя бы один из аргументов слева или справа (независимо друг от друга, хотя бы один из них). Напоминаю, операция “И” – наоборот,- чтобы результат был истина, нужно чтобы оба аргумента были истина, это выражается формой русской речи “одновременно”, т.е. “результат истина, когда одновременно левая и правая части истина”.
Начало программирования вообще с нуля. Часть 5. Клиент и сервер.
В современном мире (2023 год) все приложения и программы, с которыми мы так или иначе сталкиваемся живут в определенном виртуальном поле, называемом клиент-серверной организацией. Даже если мы запускаем обычный калькулятор на нашем планшете и предназначен он только для простых арифметических операций, он всё равно находится в клиент-серверном пространстве, просто для него ещё не придумано управляющего сервера и он выступает только оффлайн клиентом, т.е. клиентом без взаимодействия с какими-либо ещё клиентами. Если рассматриваем приложения вроде какой-нибудь социальной сети или онлайн-магазина, да что говорить, самый обычный браузер на компьютере – это полноценная часть клиент-серверного пространства, в котором им отведена почётная роль клиента. Сервера находятся где-то далеко, может быть на другом конце света, а может быть в соседнем здании и обрабатывают запросы клиентов. Так устроено это взаимодействие простыми словами. С точки зрения рядового пользователя, это просто приложение, которому нужен интернет и которое с ним как-то взаимодействует. Но мы хотим узнать с точки зрения программирования, и по этому будем рассматривать их независимо друг от друга как совершенно разные части (называемые узлами) этой взаимодействующей системы. Иногда запросов от клиентов происходит так много, что сервера не справляются и тогда было введено новое слово в обиход – “Облако”. Облачные системы – это взаимодействующие между собой сервера, которые в равной степени и взаимозаменяемо могут обрабатывать запросы от множества клиентов в рамках единой задачи. Например, облачные хранилища позволяет обрабатывать запросы от клиентов по хранению каких-либо данных. Желающих хранить данные не на своём компьютере оказалось много, по этому отдельные сервера стали не справляться и их стали объединять в единые сети обмена информации и при этом размещать в разных уголках Земного шара. Так появились облачные хранилища. По этому когда вы отправляете очередную свою фотку в “Облако”, то где она физически будет находиться в мире никто не знает, кроме самой облачной системы. Может в России, может в Африке, а может и так, что часть фотки в Бразилии, а часть во Владивостоке. Облачное хранилище само перераспределяет нагрузку, находит оптимальные алгоритмы хранения и передачи данных в зависимости от спроса, и распределяет всё что в него поступает так, как считает в процессе расчета наиболее рациональным.
Получается, что клиенты и сервер выглядят так:
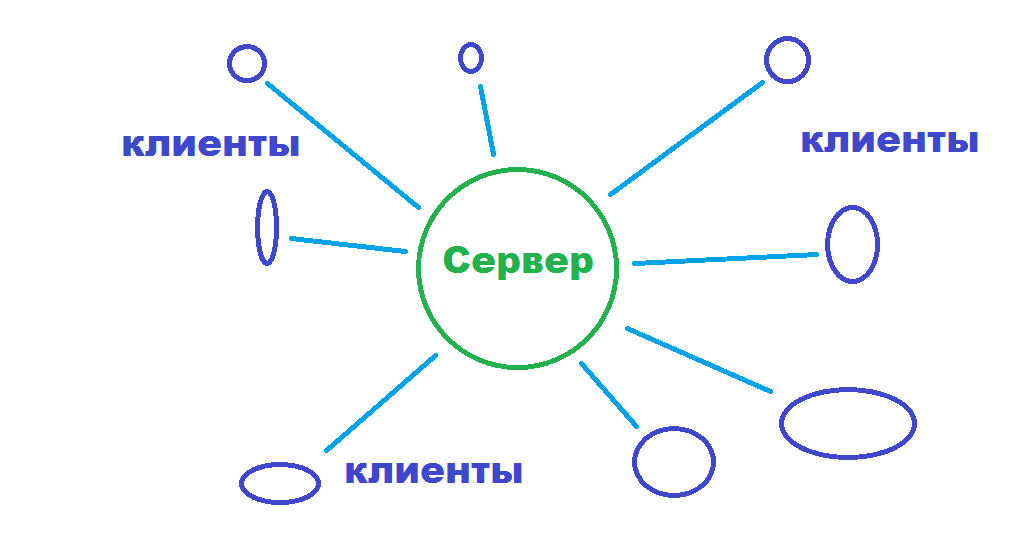
Когда речь заходит об облаке, это выглядит так:
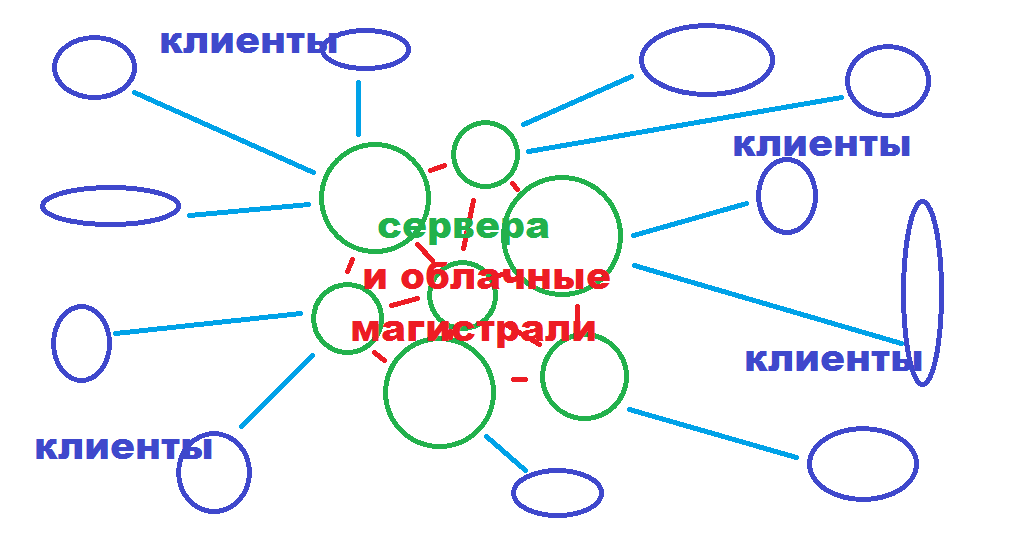
Так вот, к чему это я…С точки зрения программирования, программист должен понимать где его функционал должен работать на сервере, а где на клиенте. Например, нужно вывести сообщение пользователю, что товара нет в онлайн-магазине. Где должен выполняться этот код, на клиенте или сервере? Оказывается, что для того чтобы это действительно работало, программист должен написать для выполнения на сервере определенный код, который вычислит, что товара больше нет, передать при очередном запросе клиента, что количество некого товара равно нулю. Затем должен написать на клиенте чтобы он с определенной периодичностью опрашивал сервер на предмет изменения количества того или иного товара, принимать количество, и если оно равно нулю, то выдавать на клиенте это сообщение. Т.е. программисту нужно написать одну программу на сервере для ответной реакции по запросу клиента, и другую программу работающую на каждом клиенте, которая опрашивает сервер, выводит сообщения, принимает вводимые данные будь то клики по экрану или адрес получателя, или ваш телефон для связи. Аналогично работают и различные социальные сети. Ваш планшет с определенной периодичностью опрашивает сервер на предмет того, нет ли для вас нового сообщения, в этот момент может заодно передаёт ваше сообщение для кого-то, опрашивает не появилась ли на различных каналах ещё одна новость, не загрузил ли кто новый видос на сервер. К счастью, если вы только начинающий программист, и работаете по этой специальности недавно, то вам не придётся делать программу и для клиента и для сервера, обычно новичков ставят только на клиент и дают документацию о том как нужно обращаться к серверу (так называемые API обмена). Подытоживая сказанное, программист должен чётко и хорошо понимать, что выполняется на сервере, а что на клиенте, в связи с этим и доступные методы, классы и т.п. могут работать в зависимости от того где выполняются, а достаточно часто и могут быть вообще уникальны, только для выполнения на сервере или только для выполнения на клиенте. Например, на клиенте онлайн-магазина нельзя обратиться напрямую к базе данных сервера, а на сервере нельзя вывести сообщение для пользователя.
В клиент серверном варианте есть один нюанс. Одно дело когда у вас приложение онлайн магазина или социальной сети, другое, когда открываете страницу в браузере. Нет, не подумайте чего плохого))), и то и другое действительно клиент-серверное взаимодействие…с точки зрения организации системы. Но с точки зрения программирования, совершенно разное. Дело в том, что приложение уже написано и опубликовано, вы его скачали из магазина приложений в законченном виде, и лишь иногда делаете обновления, когда сочтёте это нужным. Если речь идет о клиент-серверном взаимодействии через браузер, то у вас нет на вашем домашнем компьютере заранее кода сайта чтобы его запустить для обмена с сервером, по этому при каждом обращении к сайту, он сначала выгружает с сервера в ваш браузер некий программный код (называемый обычно скрипт) и запускает его, и вот после этого и происходит взаимодействие клиента и сервера для обмена. Именно по этому раньше распространялось так много вирусов именно через сайты, так как играли злую шутку несовершенство операционных систем, самих браузеров и анализаторов кода, который выполнялся. При появлении мобильных приложений, перед публикацией магазин приложений почти всегда сначала проверяет его на наличие вирусов, вредоносного кода, да и сам разработчик должен быть зарегистрированным в этом магазине и предоставить свои персональные данные, чтобы было с кого спросить. С сайтами так делать в большинстве случаев не получается, т.к. нет механизма достоверной проверки кода этих сайтов (они расположены не централизированно в каком-то магазине, например, в магазине каких-то сайтов, а разбросаны в разных частях света на разных серверах и разных странах с разной юрисдикцией).
В клиент-серверной организации обмена часто всё сводится к тому чтобы передать некую информацию с одного клиента на другого. И это не только работа социальных сетей. Да, обычный онлайн-магазин – это тоже отчасти передача с одного клиента на другого – вы сделали заказ, количество товара на складе уменьшилось, и каждому клиенту рассылается новый остаток после вашего взаимодействия. Иными словами, сервер выполняет роль вычислительного звена и арбитра, можно сказать важного посредника, который организовывает всю работу взаимодействия.
Должен тут же сказать, чтобы не вводить вас в заблуждение, что клиент-серверная организация хотя и является доминирующей в мире информационных технологий, но не является единственной. Погружаться в другие на этом этапе знакомства с ИТ нет, но для эрудиции скажу, – есть ещё так называемые системы “Точка-точка” или “Пир-ту-пир”, или “peer-to-peer”, или они же “p2p”, или они же “Пиринговые сети”. Это систему у которых нет серверов вообще. Они взаимодействуют исключительно на прямом обращении одного клиента к другому, хотя было равно сказать и обращении одного сервера к другому. Типичным примером таких систем являются торрент-клиенты. В схеме это выглядит так:

По этому такие системы, или чаще говоря сети, называют децентрализованными, т.к. тут нет такого центра как сервера или облака в клиент-серверной организации. Сами же звенья этой системы не принято называть сервером или клиентом, а называют их узлами сети. Программист в таких сетях должен свою программу наделить свойствами и клиента и сервера, т.е. она должна уметь периодически опрашивать другие узлы на предмет обмена информацией, как это делает клиент, и как сервер реагировать на запросы других узлов, и отвечать им.
Клиент-серверная организация накладывает определенные правила, особенно если речь идет о взаимодействии вроде как в вашем браузере, когда вы открываете очередную страницу какого-то сайта. Дело в том, что все устройства пользователей разные, разные производители, разные комплектующие, или вообще настолько разные как iOs, Android и MS Windows, а браузер, как я только что сказал, отправляет клиенту код, который должен на нём выполняться. Определить точно не всегда удаётся ввиду того, что часто клиент скрывает достоверную и подробную информацию о своей системе ввиду информационной безопасности, а выполнить код на нём всё равно нужно. По этой причине часть выполнения была возложена на операционные системы, способные воспринимать одни и те же скрипты так, чтобы клиентский компьютер их понял, этот процесс известен ещё со времён языка Бейсик и называется трансляцией. Т.е. сервер отправляет каждому клиенту чаще всего один и тот же скрипт работающий по одинаковому алгоритму, а клиент его уже сам дополнительно анализирует и преобразует в тот код, который поддерживает его устройство. Такой подход называется мультиплатформенным, т.е. один код для разных платформ, по этому к счастью, программисту чаще всего не надо задумываться о том, какое же устройство будет конечным на клиенте, и сосредоточиться только на том функционале, который ему необходимо реализовать; конечное устройство само должно позаботиться о том чтобы правильно воспринять тот или иной скрипт.
Когда речь заходит о взаимодействии в сетях, не важно каких, пиринговых или клиент-серверных, чтобы компьютеры правильно понимали что за информацию они друг другу передают, сама передача должна осуществляться по определенным правилам, называемыми протоколами.
Здесь в терминологии есть путаница, сетью называют как физическую сеть (в виде проводов), логическую сеть, ту самую, которую мы называем интернетом, когда каждый компьютер имеет свой адрес, также называемый IP-адрес (айпи-адрес), и обращение идет по нему, и сетью ещё могут называть бесконечное количество виртуальных сетей, т.е. одних логических сетей внутри других логических сетей, например VPN-сети, пиринговые сети и т.п.
Протоколов придумано великое множество. Есть стандартные, а есть уникальные, придуманные программистами для определенных обменов. Например, есть протокол TCP, который обеспечивает выход компьютера в интернет, он стандартный и строго соответствует всегда одним и тем же правилам, по этому подключенный компьютер в интернет сразу знает как общаться с вашим провайдером или с мобильным оператором. Но есть протоколы, которые никак не стандартизованы, например различные онлайн-магазины, соц.сети. Для них обмен регламентирован только фантазией программистов организовывавших этот обмен. Однако и тут, если обменную систему разрабатывает не один программист, а целая команда, тоже потребуется вводить внутренние стандарты для этой самой команды, и ориентироваться на них. Это означает, что нельзя например взять клиентское приложение одной социальной сети, немного переделать его и оно заработает для другой социальной сети. Вероятность успеха такого подхода стремиться к нулю, и всё по тому, что протоколы обмена будут разными, придуманными своей командой разработки со своей спецификой и особенностями.
В соответствии с вышесказанным, программирование для клиента и для сервера имеет ряд отличий, а также для того и другого придуманы специальные языки программирования. Наиболее известные языки используемые для клиент-серверной организации:
Для клиента:
- Java Android (только для устройств на базе Android)
- Swift (только для систем на базе iOS)
- Javascript (только для браузеров, но для любых устройств)
- Kotlin (для Android)
Для сервера:
- PHP
- Java servlet
- Perl
- Asp
Такие языки как Си и Паскаль позволяют писать как серверное программное обеспечение, так и клиентское, но требует намного более высокой квалификации и опыта. С другой стороны, язык 1С, ввиду специфики самой платформы, позволяет писать код одновременно и для серверной части и для клиентской, при этом требует совершенно иной квалификации, чем программист Си или Паскаль, хотя сам код 1С обладает намного меньшей функциональностью.
Перечисленные языки для клиента так или иначе накладывают ограничения на то, на каком клиенте они будут выполнятся, например, на языке Java Android нельзя написать для устройств на iOS (нет таких компиляторов) и наоборот. Для Javascript нельзя скомпилировать ни для Android, ни для iOS, ни на Windows, но если на этих системах есть браузер, поддерживающий Javascript (а такие браузеры наверно сейчас все), то тогда можно этот код выполнять через этот браузер и на том и на этом устройстве, с той или иной операционной системой.
Подобных ограничений для серверов не бывает, т.к. сервер изначально настраивается на работу с тем или иным кодом (php, java servlet и т.д.) и программный код пишется под определенный транслятор или компилятор, который, как понимаете, изначально всегда известен. Т.е. программист на php сразу будет настраивать или выбирать свой сервер с установленным транслятором php, а например, программист на Java Servlet установит на сервере программу Tomcat. Сами эти языки способы делать практически одно и тоже в примерно равных требованиях к ресурсам, по этому, скорее, это дело вкуса и возможностей, на чём делать сервер.
Сам выбор языка каждый делает тоже по-своему. Я например, сторонник того, чтобы синтаксис что серверных языков, что клиентских был хотя бы чем то похож, по этому изначально выбрал Си-синтаксис подобные языки:
- Сам язык Си
- PHP
- Java
- Javascript
Они позволяют осуществлять различные программные фантазии как на серверах, так и на клиентах, и других языков я сторонюсь только по одной причине – уж больно они не похожи на Си, а часто бывает так, что на решение той или иной проблемы нужно время. Искать проблему одновременно и в серверном коде и клиентском происходит намного быстрее, если сам синтаксис языков похож. Тут нет равных языку 1С, в котором не просто один синтаксис и для клиента и для сервера, так это и есть один и тот же язык)). Плохо, что 1С требует отдельной платформы, да и сервера 1С пока ещё не бесплатные)).
El Vinto, 2023