В прошлой части мы начали говорить о бинарных данных. Давайте немного углубимся в этот вопрос. Если рассуждать по честному, то вся информация в компьютере – это бинарные данные. Отличается только их смысл и представление. Давайте откроем некий файл для просмотра и вроде как он содержит обычный текст:

Рис.1
Теперь немного изменим представление этого же файла:
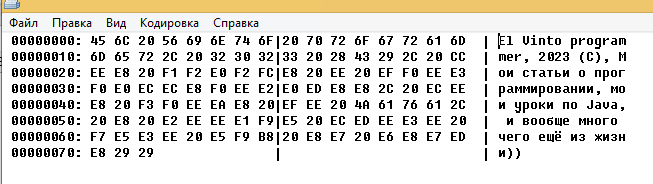
Рис.2
А теперь ещё поменяем представление на другое:
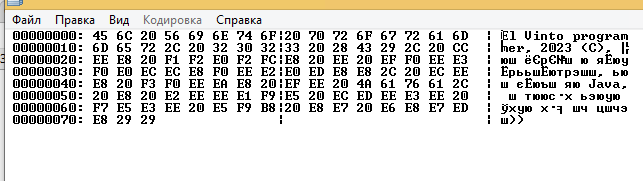
Рис.3
В средней части, как вы возможно уже читали предыдущую часть из серии “Начало программирования вообще с нуля” и догадались, хранится байтовое значение представленных с права символов. Т.е. бинарные данные. Весь представленный текст – это 115 байт информации.
Самая левая часть – это колонка с адресом, далее идут две средние колонки двоичных данных по 8 байт (всего в строке 16 байт), а справа их представление. Как можно заметить, какое бы представление не было, бинарные данные одни и те же. И это не удивительно, ведь они и есть истинная исходная информация. То, как мы хотим её видеть, в виде чисел шестнадцатиричной системы, или текстом в разных видах, вопрос другой, на самом деле данные одни и те же.
Теперь вопрос касаемый представления. Давайте посмотрим на все это немного подробнее. Заметьте, везде пробел представлен числом 20h, цифра 2 в годе 2023, представлена числом 32h. Ещё один момент, на который нужно обратить внимание – это то, что в представлении на рис.1 и рис.2 весь английский текст и цифры выглядят одинаково, а весь русский текст по разному. Дело в том, что тут есть одно правило. Все символы латинского алфавита, цифры, знаки препинания, пробел и ещё некоторый набор символов являются представлением байта со значением меньшим 128, т.е. байты 00-7Fh, и за каждым значением всегда закреплен определенный символ. Диапазон 80-FFh – это пользовательские символы представляемые определенной кодировкой (но есть небольшое исключение). Казалось бы, зачем было так делать?
Когда-то давным давно, когда каждый день вызывал перерождение компьютерной идеологии, большая часть информации вносилась на английском языке. Однако, в процессе интеграции компьютеров по всему миру, его стали использовать для отображения текстов на русском, немецком, французском, японском и т.д. языках. Сначала, до появления WIndows, за то, в какой национальной среде какие 2(!) языка использовать (английский и ещё какой) отвечали настройки операционной системы. Затем, когда стали вдруг появляться тексты сразу на нескольких языках (на одном рабочем месте), стали использовать отдельные символы. Ну, например, 00-7Fh – это всегда английские, 80-FFh – это как бы русские, но есть ещё несколько символов из испанского, такие, например, как ò (ударная о) или è (ударная е), также туда были добавлены некоторые буквы норвежского языка, например, å, и т.п. В общем, с горем по полам, как-то писались тексты. Проблемно стало, когда в языки стали включать иероглифы, которых, как мы понимаем, несколько больше, чем все алфавиты романской группы и кириллицы. Нужно было что-то менять. Стали придумываться разные кодировки, но беда была в том, что либо туда что-то не попадало, как кодировка ASCII или ANSI, либо туда попадало всё, но текст стал занимать место на дисках в несколько раз больше. В то время дисковые накопители обладали размером в сотни тысяч раз меньшим, по этому такое расточительное хранение текста считалось недопустимым. Со временем диски стали лавинно увеличиваться в размерах, а программисты искали методы для более эффективного хранения текстовой информации. На стыке одного и другого и произошли радикальные изменения. Но история об этом хранится, и теперь от старых кодировок быстро не отделаться, т.к. много текста хранится в них. Также есть старые операционные системы или микрокомпьютеры, где не нужно хранить текст, например, на китайском, а достаточно хранить на английском. Например, моя посудомоечная машина Ariston может вообще показывать только цифры и буквы P и E, зачем управляющей ей операционной системе хранить текст в современной кодировке? Кстати и стиралка тоже лексиконом не блещет)). Наиболее же перспективной кодировкой на 2023 год является кодировка UTF-8, она позволяет хранить текст одновременно на всех алфавитах (в т.ч. и иероглифы), даже например такие как Ѭ, Ѧ. Это всё потому, что под каждый символ национального языка, выделяется памяти больше одного байта. Также на правильное представление влияет не только в какой кодировке хранится текст, но и какая кодовая таблица используется. Т.е. кодировка из текстовой строки получает набор кодов символов, вторая таблица коды символов ассоциирует с определенным знаком/символом/буквой/иероглифом. Кодовая таблица сейчас используется unicode.
По этому, говоря о данных находящихся в компьютерах, принято иногда характеризовать о каких данных идет речь, о бинарных или нет. В итоге, например, нельзя просто сказать “Пришли мне бинарные данные надписи Привет, мир!”, потому что она содержит текст на национальном языке и не понятно в какой кодировке тебе их прислать. В кодировке ASCII это будут вот такие бинарные данные:

В кодировке UTF-8 это будут уже такие бинарные данные:

Как видите строка UTF-8 занимает куда больше места, хотя это тот же самый текст “Привет мир”. Однако, попробуем закодировать ещё и надпись “Hello world”, в ASCII это будет:

а в UTF-8:

Видно, что последовательность бинарных данных для текста “Hello world” одинаковая 48 65 6C 6C 6F 20 77 6F 72 6C 64. Каждому байту соответствует символ, что не скажешь о русских буквах. Получается, что если текст содержит только латинские символы, знаки препинания, цифры (это все символы с кодом меньшим 80h), то количество байт, требуемых для хранения такого текста равно количеству символов. Если текст содержит символы на национальных языках, то количество байт для хранения требуется больше.
С хранением строк должно быть немного понятно, а что с хранением в компьютере чисел. Дело в том, что как мы уже знаем, в одном байте можно хранить только целые числа от нуля до 255, а в двух байтах (по законам математики) от нуля до 256*256-1 = 65536, в 4-х байтах от нуля до 256*256*256*256-1=4294967296 и т.д.
Но мы знаем, что числа бывают отрицательными, как быть с этим? Здесь мы должны сначала определиться сколько мы будем выделять байт под число. После этого нам придётся пожертвовать одним (старшим) битом числа для определения знака. Если этот бит будет равен нулю, то это будет положительное число, а если 1, то отрицательное. Т.е. например, если нам нужно выделить переменную, которая будет хранить целое положительное число гарантированно не превышающее 255, то нам достаточно одного байта. Если же при этом число может быть отрицательным, то тогда уже без 1 старшего бита, т.е. только число не более 127 и не менее минус 127. Это может, например, использоваться тогда, когда вам нужно хранить проценты от 0 до 100% или от -100% до +100%, да мало ли ещё для чего может быть использован такой небольшой интервал. Однако, что с бинарными данными числа? Рассмотрим, например, бинарный байт E5h. Какое число в нём хранится, минус 27 (-27) или плюс 229 (+229)? Ведь с точки зрения бинарных данных и то и это будет E5h. Здесь тоже, как и со строкой, необходимо знать заранее, что это за бинарные данные. Если байт хранит целое положительное число, то тогда это 229, а если целое знаковое число, то уже -27. Это всё потому, что у E5h ( равен 1110 0101b ) старший бит единица и для знаковых чисел этот бит интерпретируется как признак минуса, а для беззнаковых чисел он просто ещё один старший бит числа.
Однако, я уже сказал, что целые числа могут храниться не только в байтах, но и в словах (это термин обозначающий 2 байта подряд – WORD), двойных словах (4 байта – DWORD) и т.д. Давайте посмотрим на это же число 229, если хранится в 2-х байтах. Бинарные данные тогда для него будут такими:
00 E5
Но оно и понятно – вот они два байта, старший байт нули, т.к. для этого числа и одного байта хватает, а младший байт всё тот же E5h. Однако, при хранении этого числа в двух байтах, старший бит (15-й по счёту) никогда не будет единицей – старший же байт целиком ноль. По этому становится не важным, перед нами 2 байтовое число знаковое или беззнаковое, оно всегда будет представлено как +229. Чтобы оно стало вдруг минус 27, бинарные данные должны быть такими:
FF E5
Но опять-таки это правило будет работать только для чисел не превышающих 2^15 (2 байта это 16 бит, но без знакового бита – 15). Как только число будет больше, уже опять нужно заранее знать знаковое там целое число или беззнаковое.
Из этого примера должно стать ясно, что в компьютере бинарные данные – это просто набор байт. То, чем это является на самом деле, текст, картинка, видео, файл экселя, файлы каких-то программ, решать пользователю, системе и прикладным программам, ну и конечно же программисту; они должны знать какой смысл этих бинарных данных, с которыми они работают.
В связи с этим во многих языках программирования чтобы задать переменную необходимо явно указать, что это за переменная – строка, байт, целое число под которое выделено 2 байта, 4 байта или даже 8 байт, а может это вообще вещественно число (число с дробной частью). Также, если это целое число, нужно указать есть ли у него знак или его нет. Исключение составляют вещественных числа – для них признак знака не указывается, т.к. физически сложно представить задачи, где нужно хранить дробное только положительное число. В связи с этим есть примерный ориентир при объявлении переменных:
byte a; // выделяется 1 байт, хранит целое число беззнаковое число
short int b; // выделяется 2 байта, хранит знаковое число
unsigned int c; // выделяется 2 байта, хранит беззнаковое число
int d; // выделяется 4 байта, хранит знаковое число
unsigned int e; // выделяется 4 байта, хранит знаковое число
long f; // выделяется 8 байт, хранит знаковое число
unsigned long g; // выделяется 8 байт, хранит беззнаковое число
long long h; // выделяется 16 байт,…
float i; // выделяется 4 байта, хранит вещественное число
double j; // выделяется 8 байт, хранит вещественное число
Хотя некоторые современные микропроцессоры поддерживают знаковый байт, компиляторы делать этого не позволяют, т.к. этот формат считается устаревшим и слишком специфическим.
Иногда для старых процессоров или процессоров для микроустройств, концепция немного изменена, особенно если процессор 32-битный или 16-битный. Там под int выделяться может только 2 байта, а под long – 4. Но обычно такая нестыковка проблем не вызывает, т.к. любой современный компилятор при необходимости может сообщить сколько же он будет выделять памяти под ту или иную переменную.
Со строками не так всё однозначно. Если программист захочет узнать сколько же байт памяти занимает у него в строке, то пока он не выгрузит эту строку в бинарные данные, не сможет этого подсчитать. Опять-таки за счет того, что строка может быть в разной кодировке – нужно сначала раскодировать строку в бинарные данные, а потом уже считать.
Существует ещё миллионы различных представлений бинарных данных, кроме строк, тут всё зависит только от того, какой в них был первоначальный смысл. Например, бинарные данные:
65 65 65 65
Что это? Это строка из 4-х символов “eeee”, это беззнаковое число int равное 1701143909, а может это программист тут хранит картинку 2 на 2 точки и 65h – это оттенок серого каждой точки? А может это часть сэмпла какого-то музыкального произведения, а может это исполняемый код процессора? Если заранее это не известно, для обычного читателя этих байт – это просто бинарные данные.