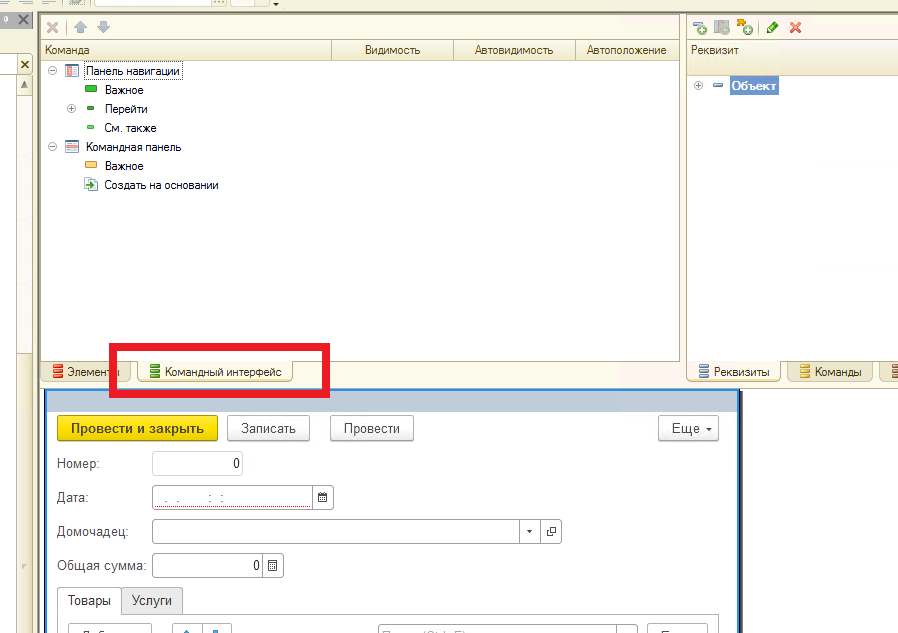
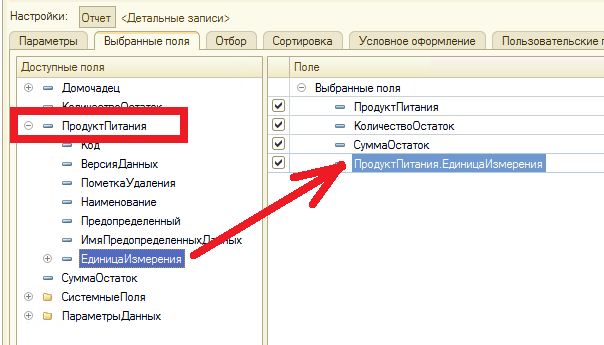
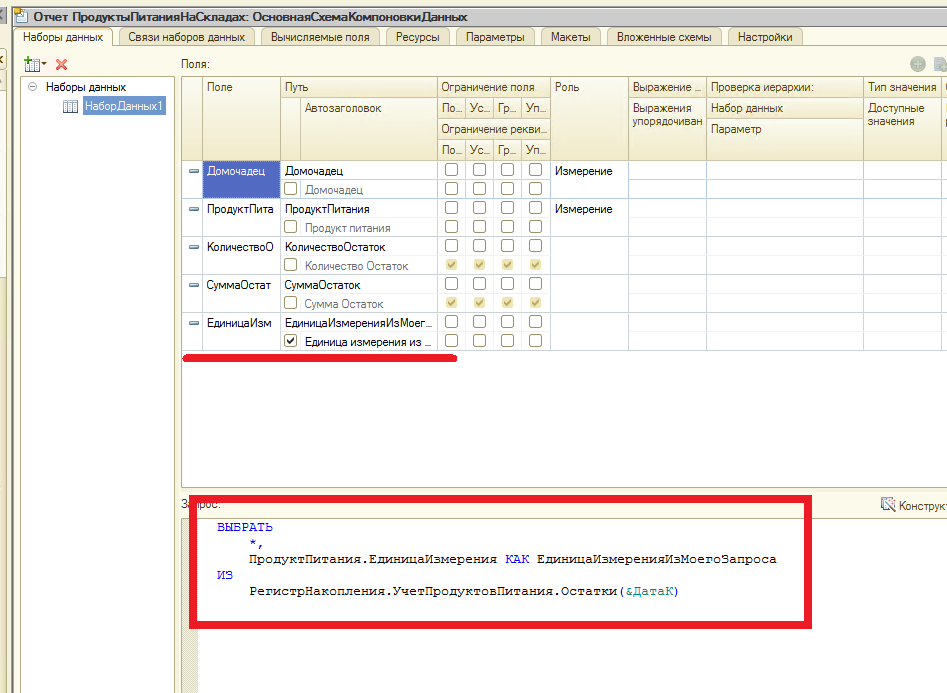
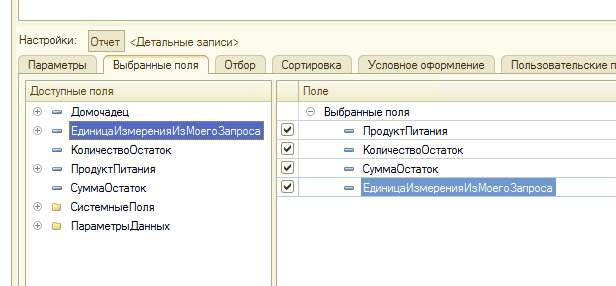
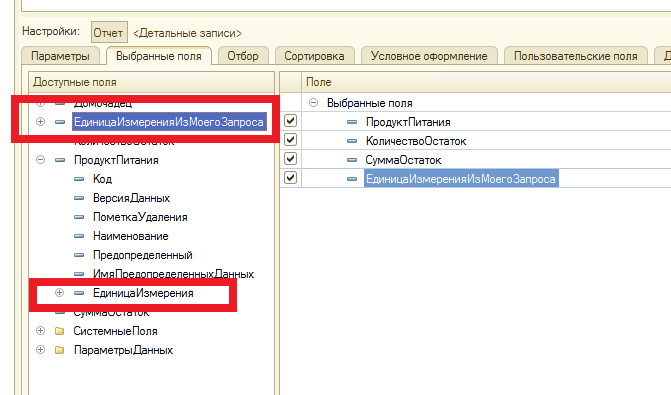
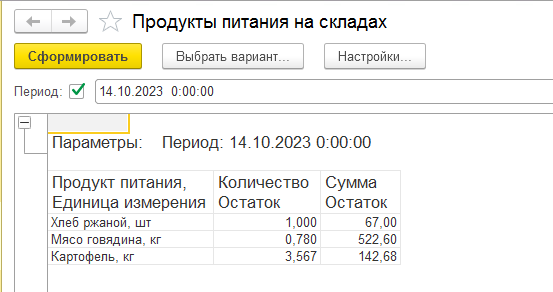
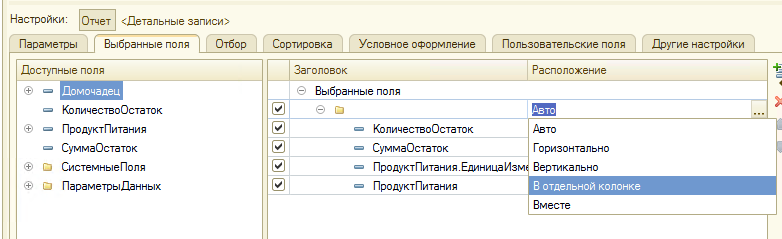
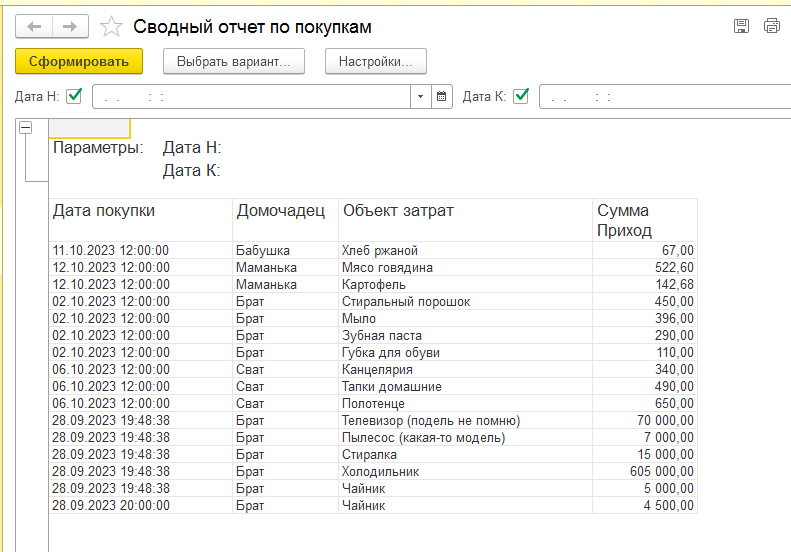
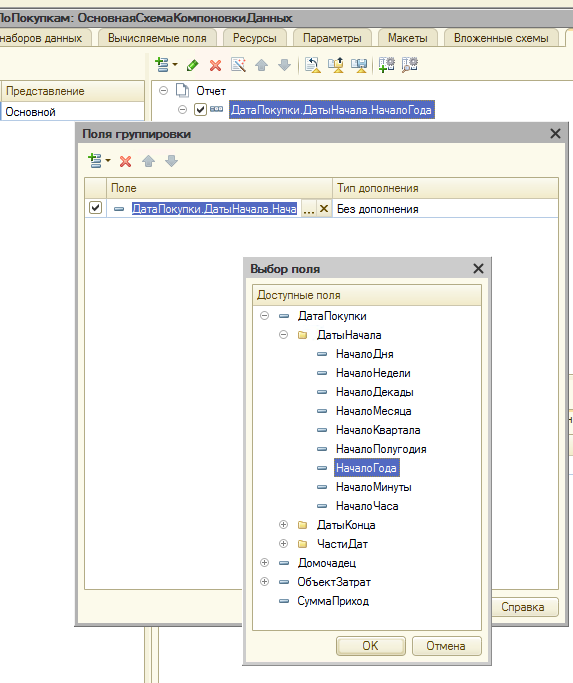
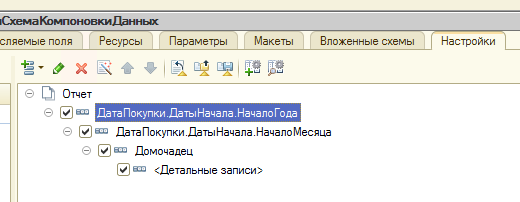
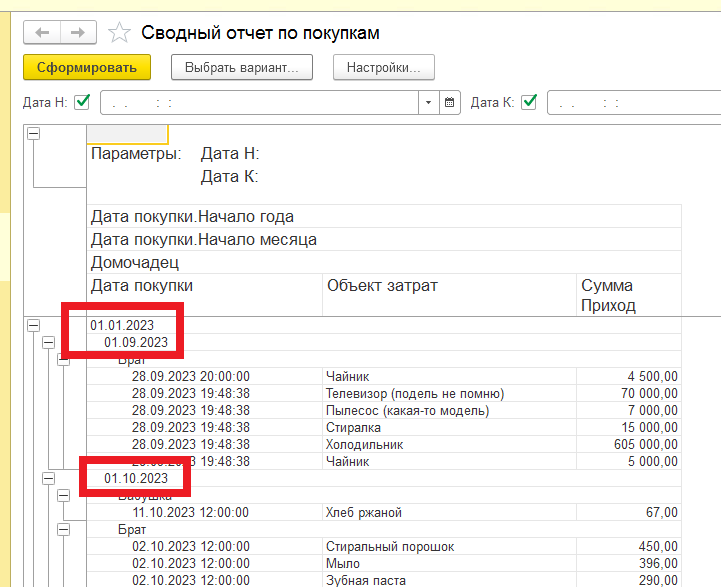
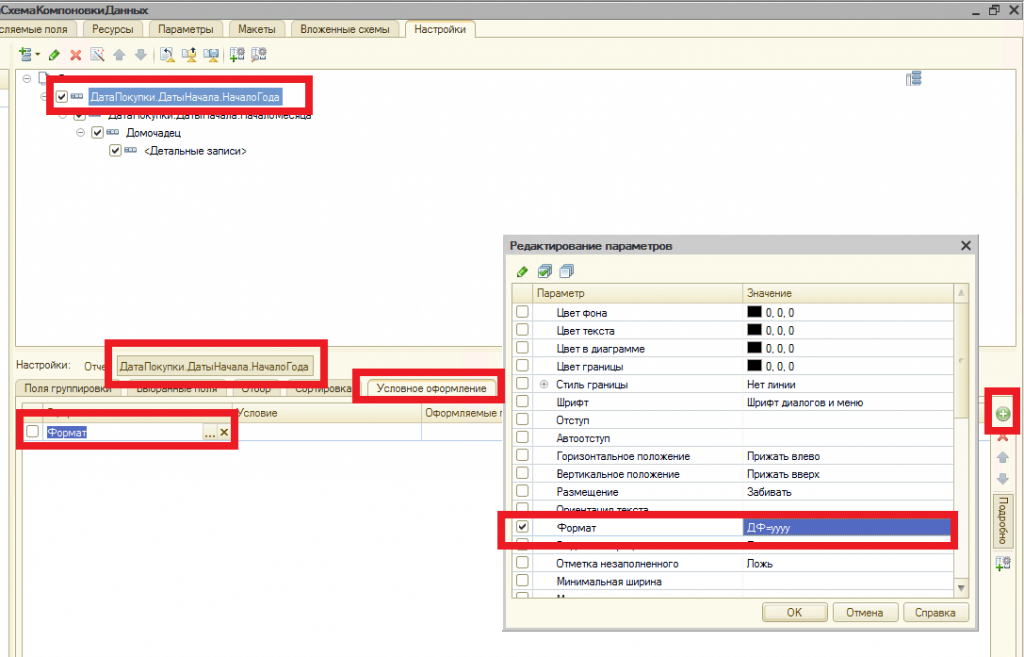
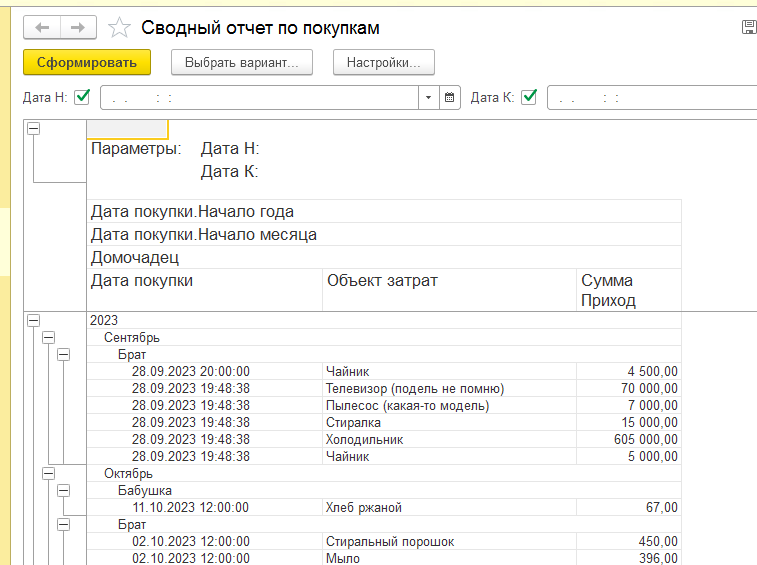
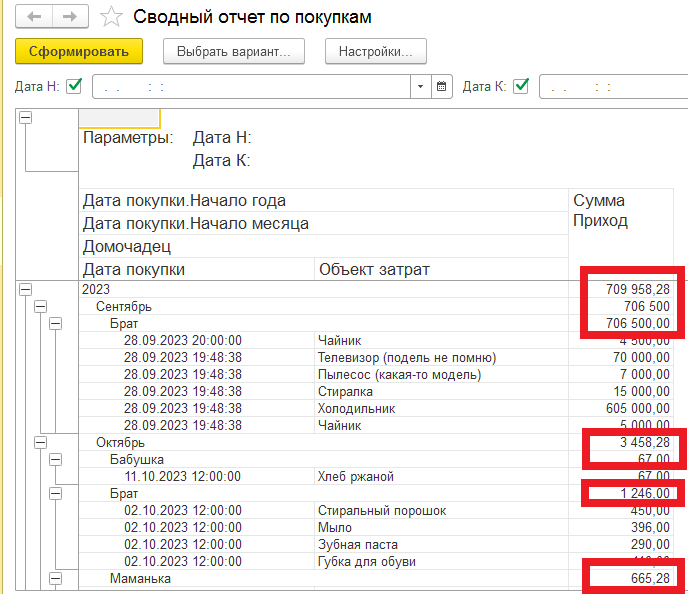
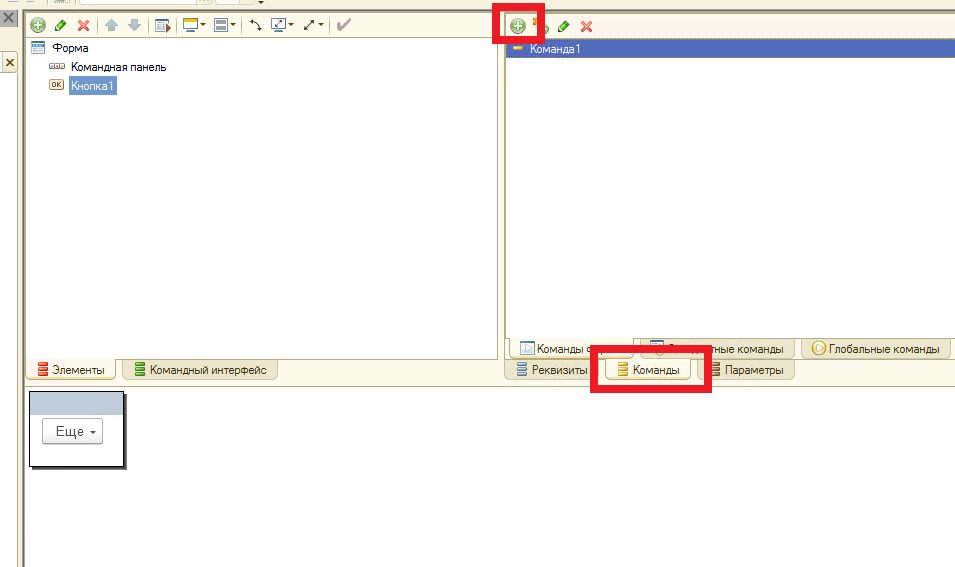
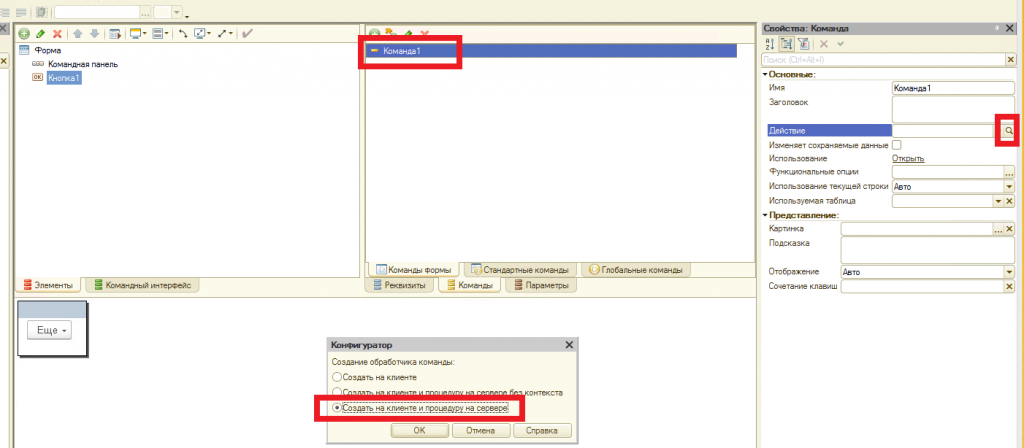
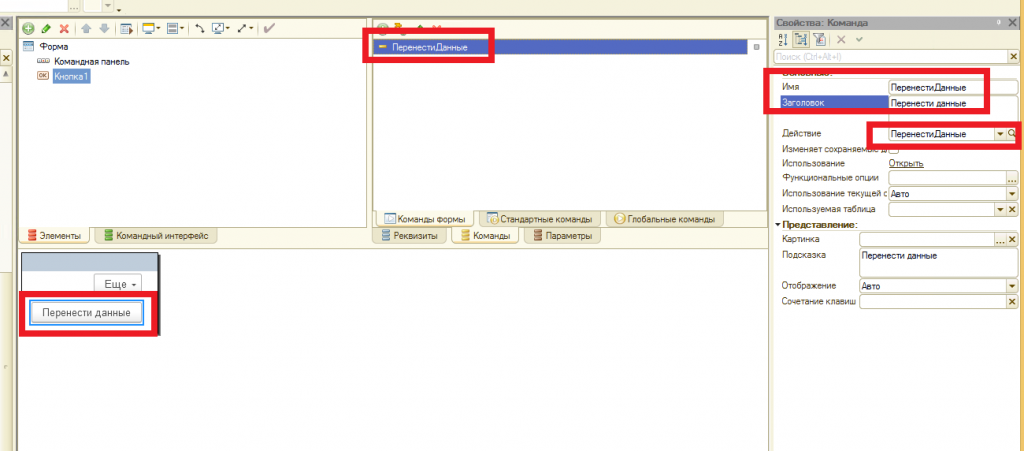
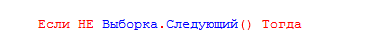В этом уроке продолжим изучение 1С. На прошлом занятии мы начали пробовать делать свои первые отчеты на базе СКД, но глубоко не вникали в эту тему. На этом уроке будем более расширенно погружаться в эту тему.
Настало время более подробно познакомиться с языком запросов 1С. В основе этого языка, как я уже говорил, находится язык SQL. Однако, в 1С он используется с одной стороны не полностью, а с другой, ввиду специфики самого 1С, в него добавлены те конструкции, которых нет в базовом SQL. В 1С язык используется для получения данных из базы. Обратиться можно практически ко всему, что хранит в себе рабочая среда конфигурации 1С. Т.е. мы создаём справочники, документы, регистры, и всё это можно получить через язык запросов. Сам же этот язык используется не только для СКД, но и в других областях программирования 1С, например, при проведении документов, при написании различных обработок, выгрузки данных в другие системы и т.п. Для примера возьмем нашу конфигурации. Помните, на одном из прошлых уроков мы делали документ поступления и документы списания. Давайте рассмотрим типичную для любого бизнеса ситуацию, опять-таки на примере чайников. Мы купили 5 чайников одной и той же модели по 1000 руб чтобы подарить их на Новый год нашим гостям. Потом узнали, что гостей будет не 5 человек, а 8. Кого-то обидеть было бы нехорошо, по этому решили докупить ещё 3 таких же чайника. Приходим в магазин, а они уже не по 1000, а по 1500 руб за штуку. Делать нечего, купили ещё три штуки. Потом, оказалось, что гостей пришло не 8, как мы ожидали, а 6 человек. Т.е. у нас останется 2 чайника лишних и мы решили их продать по объявлению. Вопрос на засыпку – какая себестоимость каждого из 2 оставшихся чайников? За какую цену нам их продавать чтобы не остаться “в минусе”? Ведь мы дарили 6 чайников и конечно же не маркировали их за сколько они нам обошлись. А покупали по разным ценам – по 1000 и 1500. Как узнать теперь сколько стоит каждый чайник из этих двух? Тут одним из подходов в такой ситуации является метод средневзвешенной цены по формуле:
СредневзвешеннаяЦена = (Количество1 * Цена1 + Количество2 * Цена + …) / (Количество1 + Количество2 + …)
Т.е. мы суммируем произведение количество на цену при каждой покупке. Получается, что после приобретения всех 8 чайников у нас будет так:
СредневзвешеннаяЦена = (5 * 1000 + 3 * 1500) / (5 + 3) = 1187.50 руб.
Это как раз и есть та самая себестоимость каждого чайника после покупки всех восьми. Продавая ниже 1187.5 мы будем “в минусе” (будет для нас затратно).
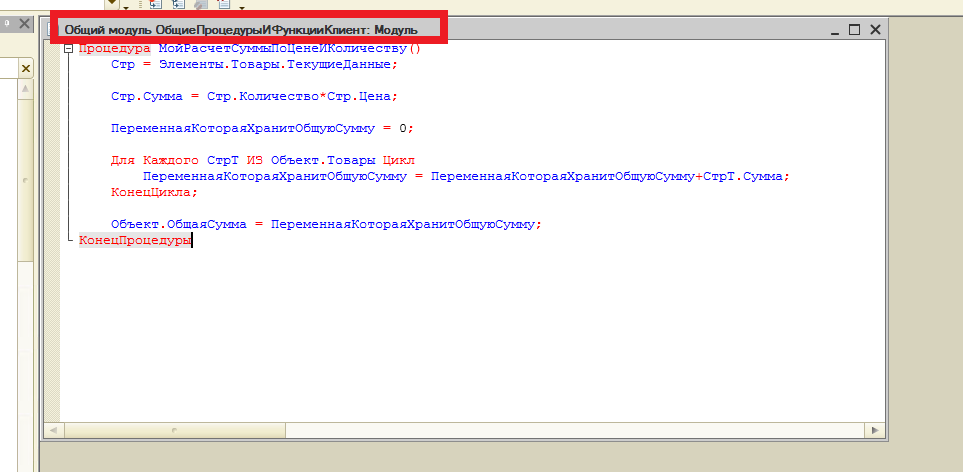
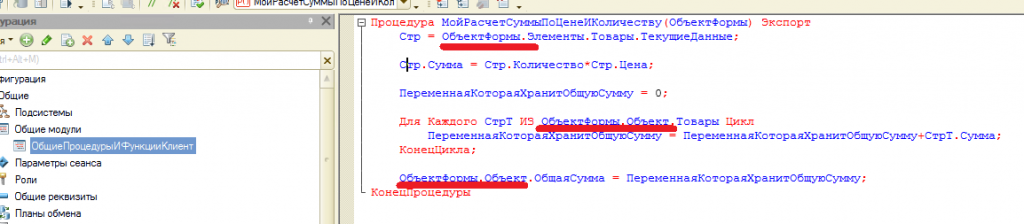
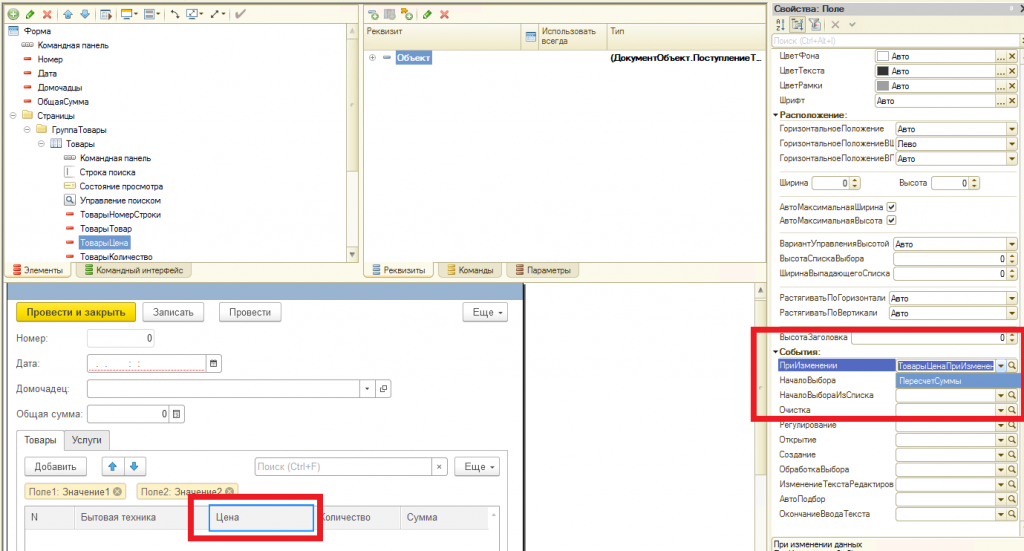
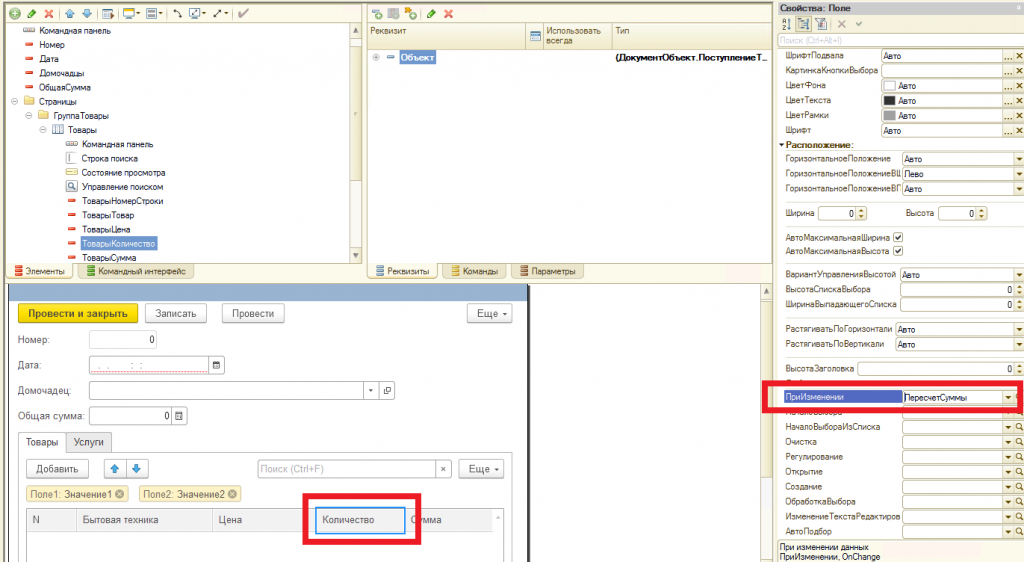
Теперь вернёмся к наше конфигурации 1С. Мы в регистр накопления “ТоварыНаСкладах” добавили два ресурса – количество и сумма. И это не случайно почему я так сделал. Обратите внимание, что средневзвешенная цена это ничто иное как:
СредневзвешеннаяЦена = СуммаИзНашегоРегистра / КоличествоИзНашегоРегистра
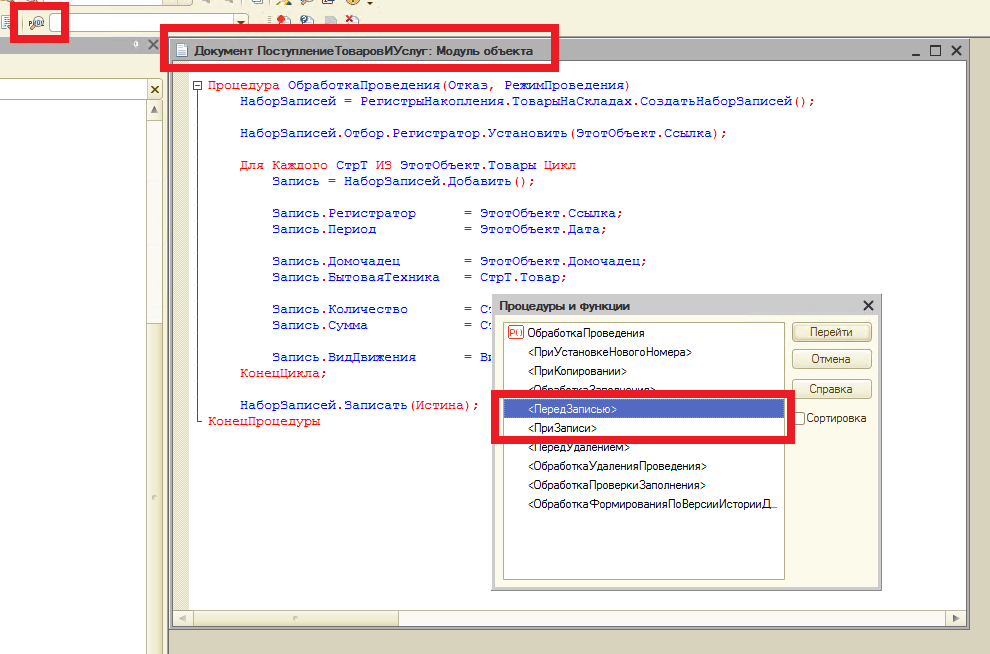
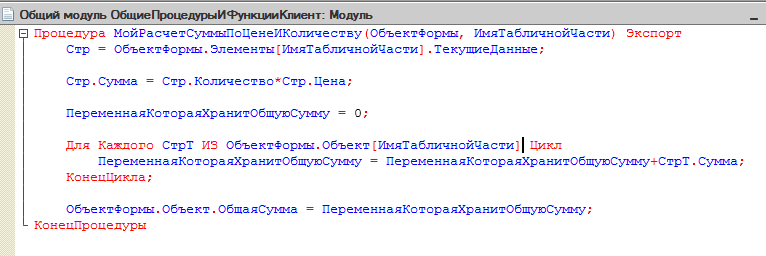
Т.е. все в нашем регистре уже есть чтобы найти средневзвешенную цену каждого товара. А что делать с продажей, давайте посмотрим на нашу обработку проведения при реализации. Скорее всего там окажется как-то так:
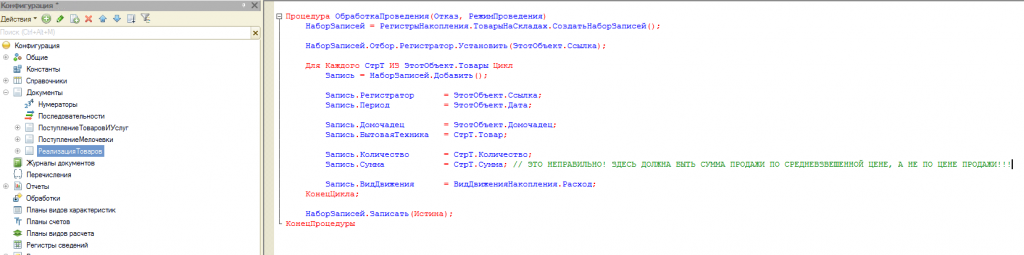
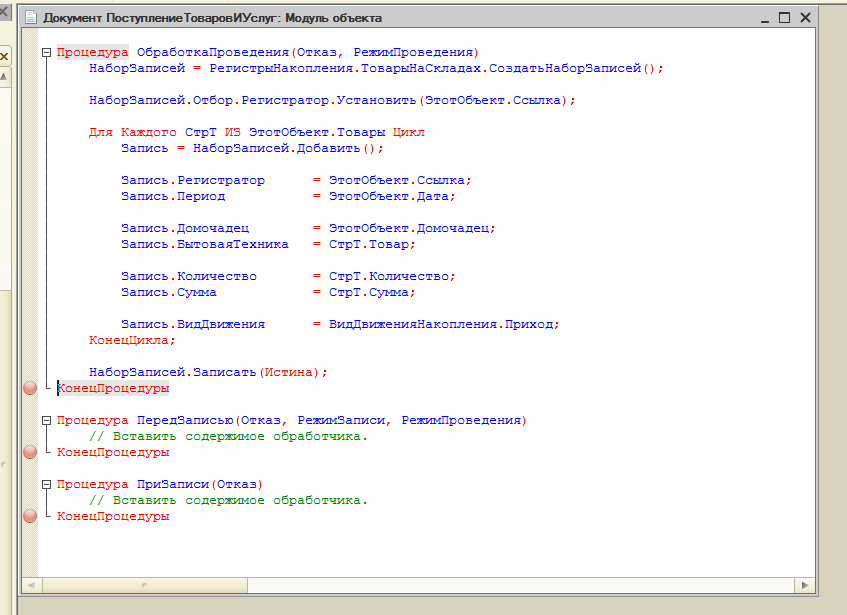
И действительно – нужно списывать суммовые остатки не по цене продажи, а по средневзвешенной цене. Тогда после реализации будут правильные остатки и оставшегося товара.
На самом деле учет средневзвешенной цены не единственный. Есть ещё учет, когда сначала списываются более ранее приобретенные товары или есть учёт, когда сначала списываются более поздние приобретенные товары. Эти способы называются соответственно FIFO и LIFO. Какой способ выбрать зависит от той или иной политики определенной организации и решается управляющим комитетом компании. Но для нашей конфигурации я волевым решением принял способ по средневзвешенной цене.
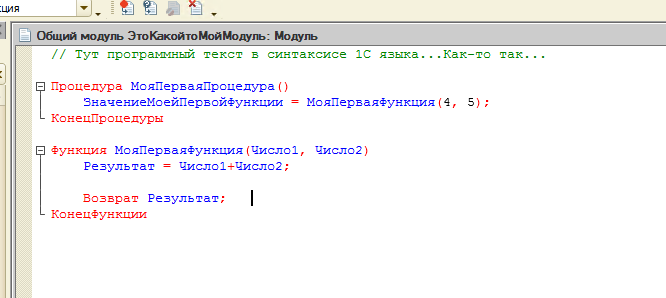
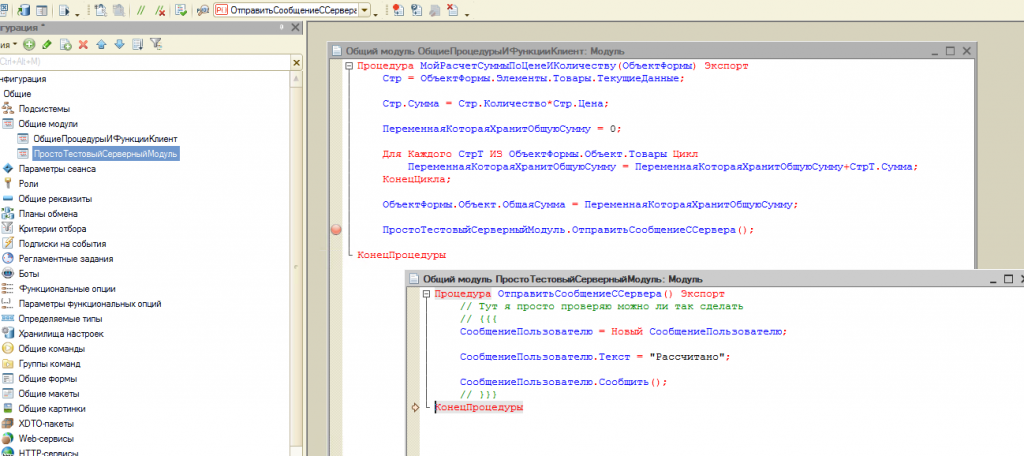
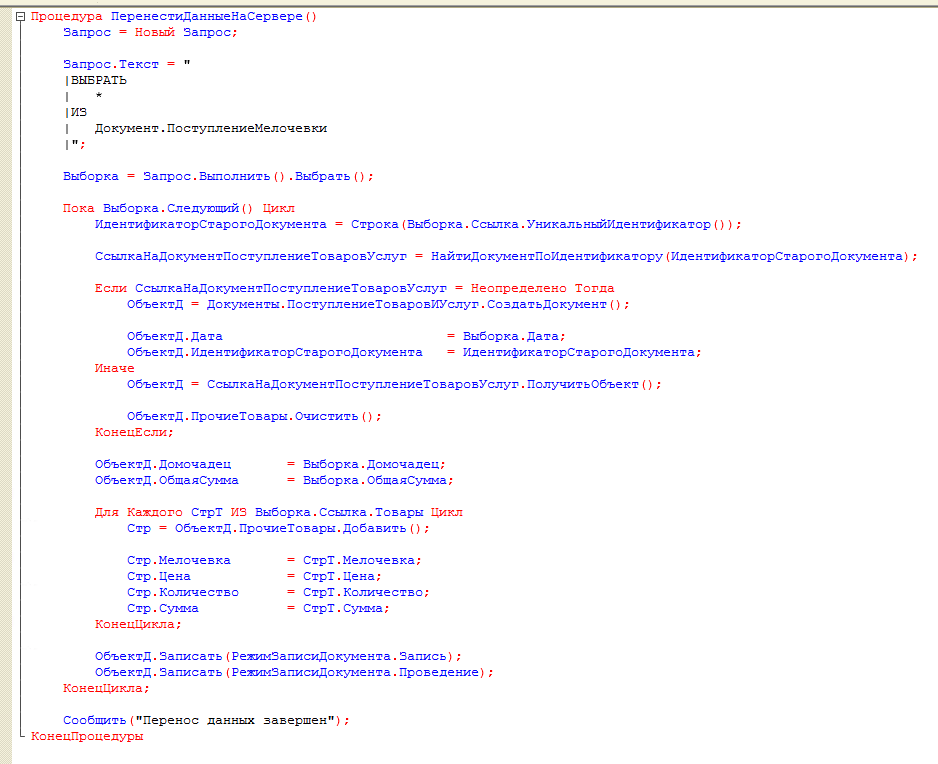
Но как же нам тут посчитать эту цену с точки зрения 1С? Делаем это так:
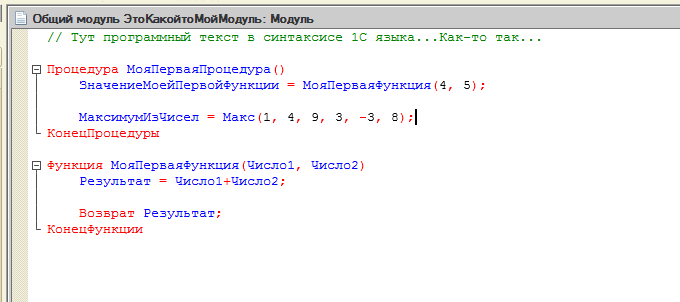
И чуть далее самое главное так:

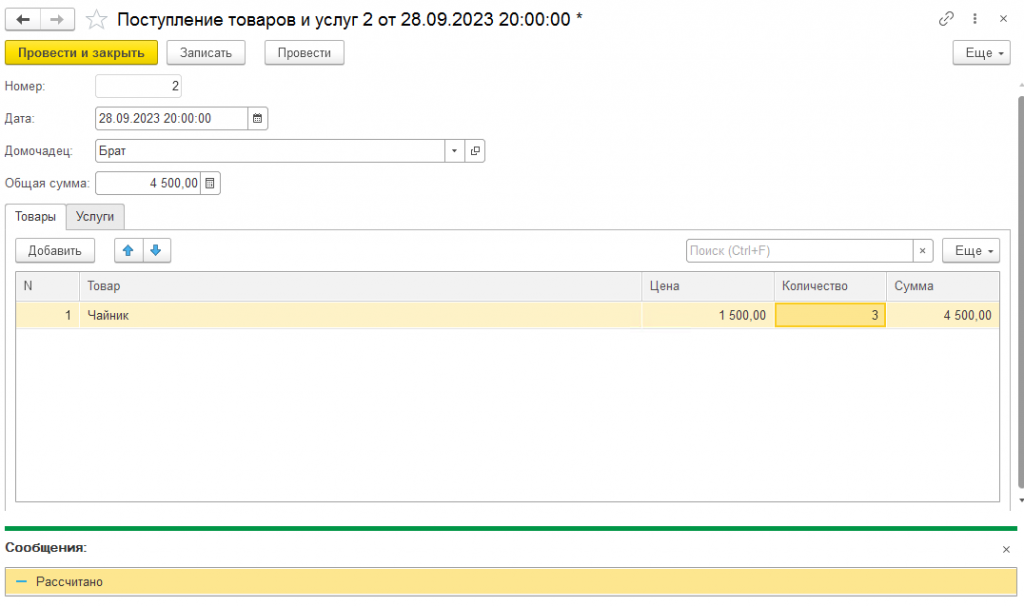
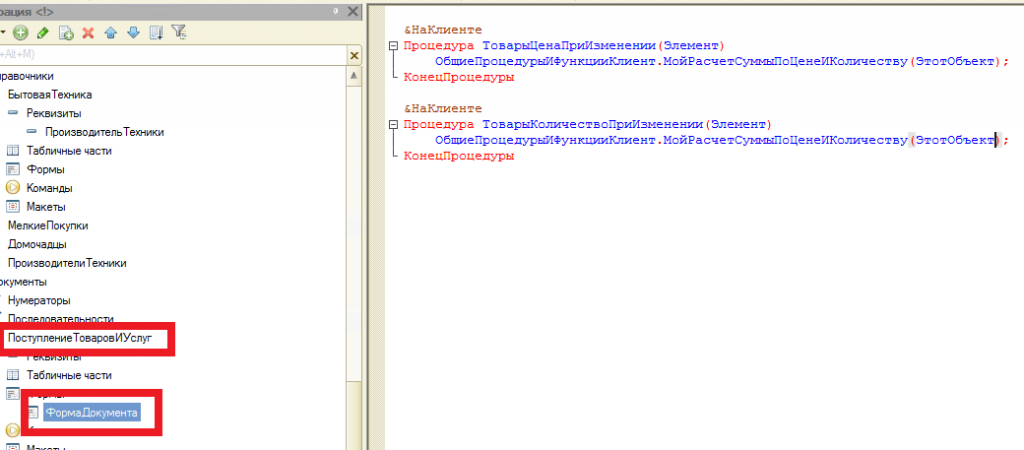
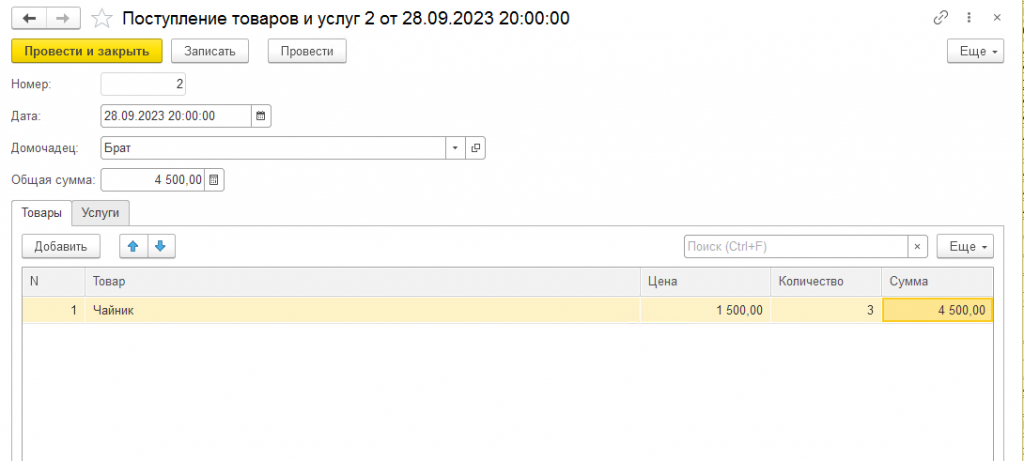
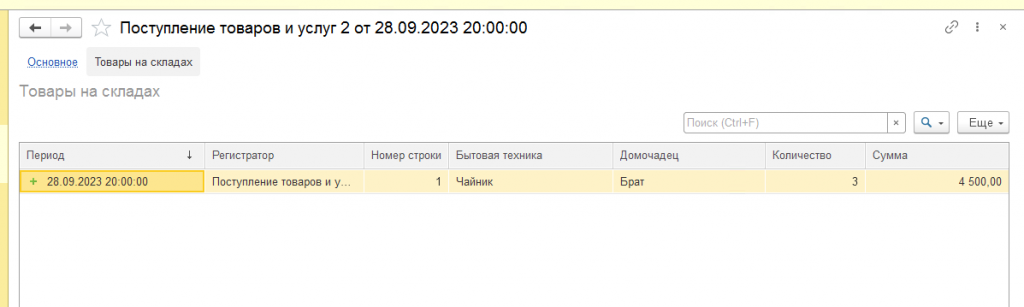
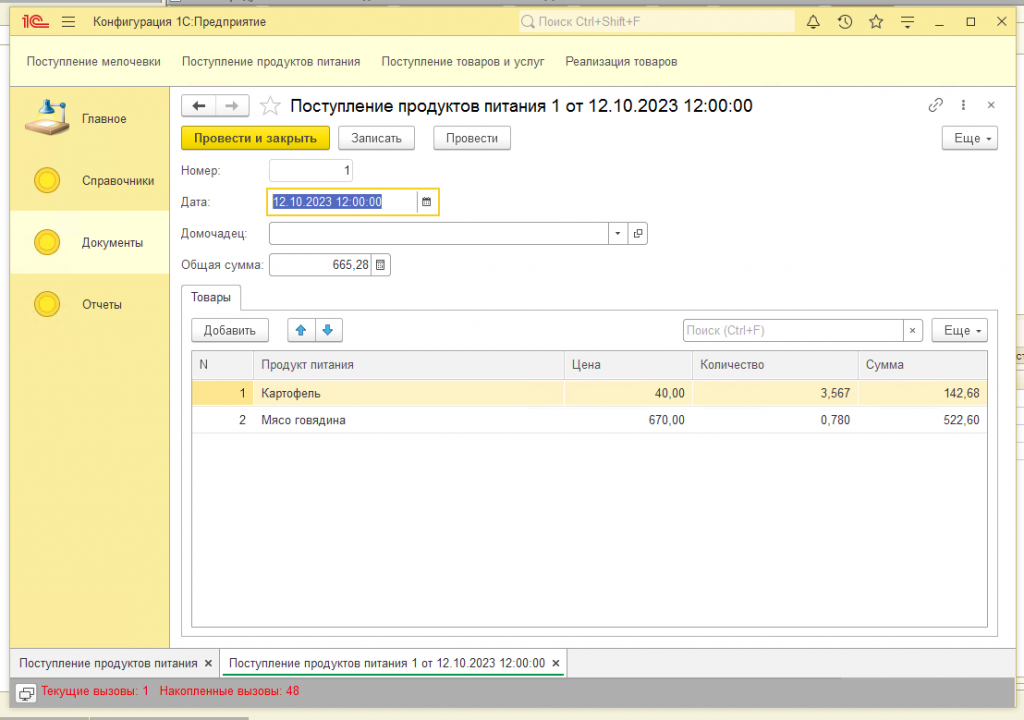
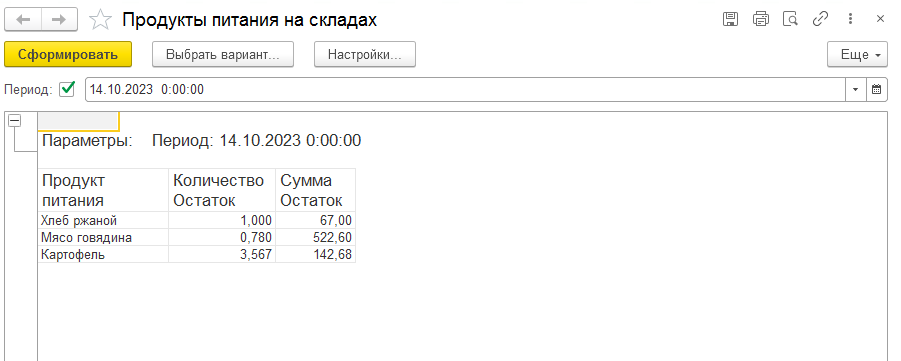
Теперь сначала добавим ещё один документ покупки чайников (где мы покупаем 3 штуки по 1500). Далее изменим документ реализации чайников, указав там, что продали мы не 2 штуки, а 6 штук. Проведем его и проверим содержимое регистра, что с чайниками теперь всё ок:
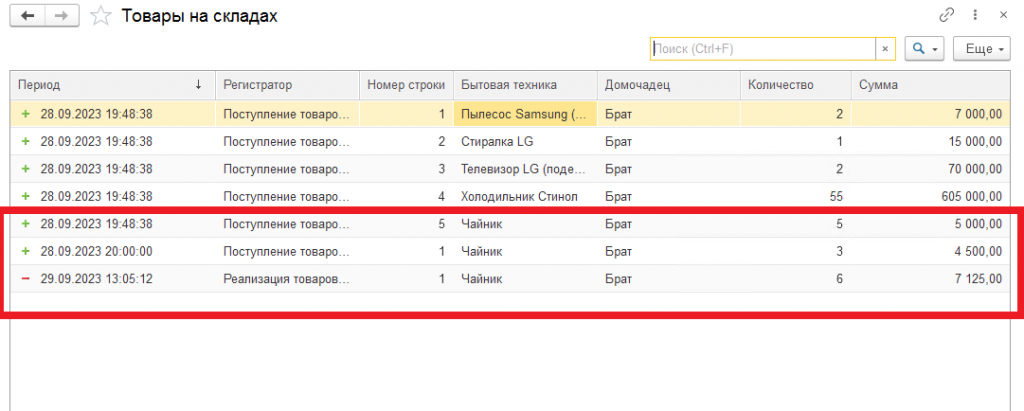
Да, всё как и хотели – купили 5 по 1000, ещё докупили 3 по 1500 и продали 6 по 7125. Ещё раз заметьте, что продали мы не на сумму 7125 руб., т.к. продали мы на самом деле на сумму 1200 (это цена продажи) * 6 = 7200 руб., а продали мы по себестоимости 7125 руб. 7125 – это себестоимость проданных товаров, т.е. за сколько они нам обошлись при покупке (разумеется по средневзвешенной цене).
Внимание! Здесь документ, где мы докупаем ещё 3 чайника, должен стоять по времени после первого документа покупки и перед документом продажи.
Давайте разбираться что тут происходит.
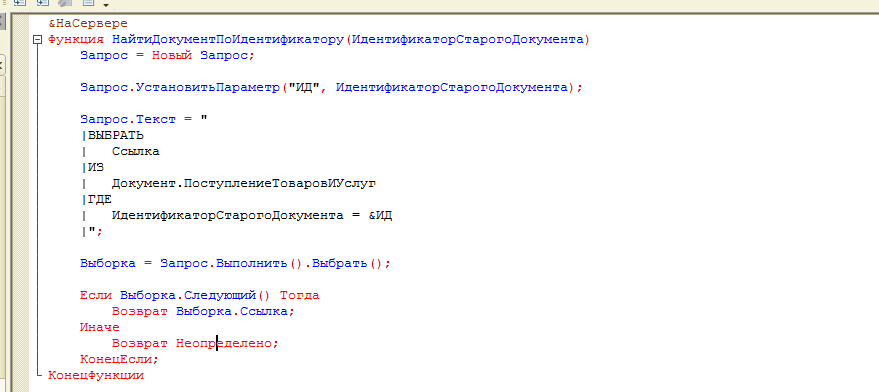
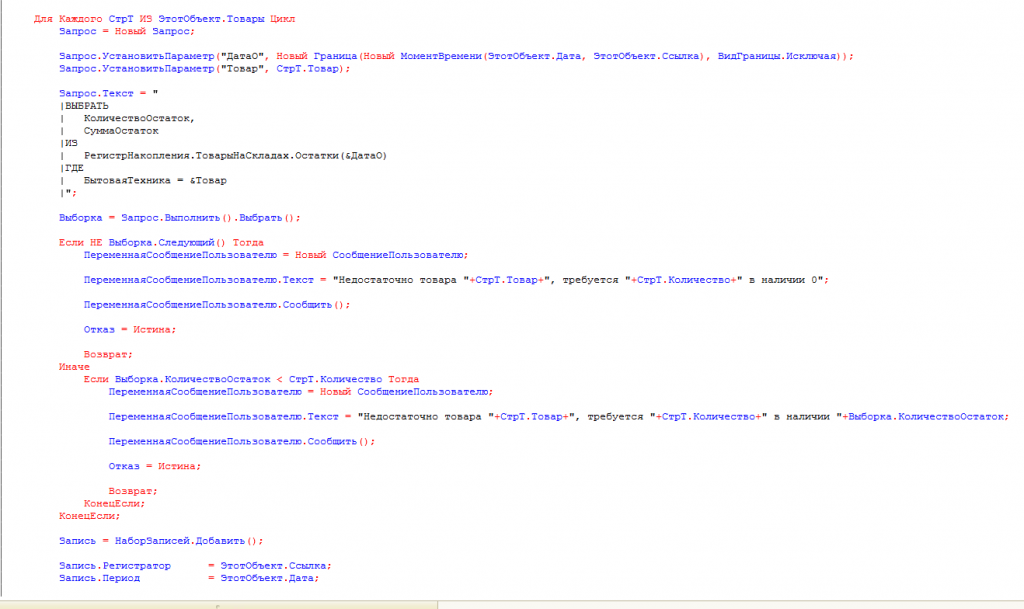
Сначала мы создаём объект запроса и передаём в него параметры, по которому будем фильтровать результат:
Запрос = Новый Запрос;
Запрос.УстановитьПараметр(“ДатаО”, Новый Граница(Новый МоментВремени(ЭтотОбъект.Дата, ЭтотОбъект.Ссылка), ВидГраницы.Исключая));
Запрос.УстановитьПараметр(“Товар”, СтрТ.Товар);
Параметр ДатаО – это дата и время, на которое нам нужно получить остатки каждого товара. Казалось бы, давайте сюда просто напишем дату документа и всёго делов-то! Но нет, так неправильно. Дело в том, что пользователь может документ провести повторно (ну забыл он провёл его или нет или просто привык закрывать кнопкой “Провести и закрыть”, или что-то поменял и решил перепровести). Что тогда получится в этой казалось бы безобидной ситуации? А получится вот что – программа увидит дату самого документа (а как я уже сказал, документ уже и так проведен) и возьмёт момент времени ни до того как его провели, а сразу после этого момента времени – по-умолчанию). Т.е. дата одна и та же, но момент времени до проведения документа и после его проведения – это существенная разница! Ведь после проведения количественный остаток уже будет не 8 штук чайников, а за минусом того, сколько мы уже списали этим документом когда прошлый раз его проводили. Если бы мы сначала распровели документ (отменили проведение), а потом стали бы проводить заново, то такой проблемы не возникло бы. Но как я уже сказал, пользователь может повторно проводить уже проведенный документ. В этом случае программе нужно сказать, что мы исключаем момент времени самого документа. Делается это такой непростой конструкцией.
Второй параметр – это фильтр по Товару, ведь нам для каждого проводимого в документе товара нужно посчитать его себестоимость отдельно.
Сам запрос тоже стоит разобрать:
|ВЫБРАТЬ
| КоличествоОстаток,
| СуммаОстаток
|ИЗ
| РегистрНакопления.ТоварыНаСкладах.Остатки(&ДатаО)
|ГДЕ
| БытоваяТехника = &Товар
Когда мы в прошлый раз писали его в СКД, там было как-то похоже, только без знака “|” (вертикальная черта). Дело в том, что в СКД, в предназначенное для запроса поле, ничего писать иное не предполагается, а в языке 1С в кавычках указываются текстовые константы и чтобы их можно было переносить по строкам, нам придётся сообщить о своём намерении платформе 1С и ставить этот служебный знак вначале строки.
Запросы 1С состоят из двух обязательных частей, которые выглядят так:
ВЫБРАТЬ ПоляКоторыеНужноВыбрать ИЗ ОткудаВыбратьЭтиПоля
К тексту запроса можно добавить условие, как это сделано у меня:
ГДЕ БытоваяТехника = &Товар
Вообще по строкам принято переносить исключительно для более лёгкого понимания самого программиста, чтобы он быстро мог вспомнить что там написал или понять что там написал другой программист. Чем легче читать код или текст запросов, тем быстрее можно решить поставленную задачу.
Таблица откуда брать тоже похожа, только вот таблица немного другая и параметры для неё другие. Помните, в СКД мы брали таблицу ОстаткиИОбороты, а тут только Остатки. Соответственно, у остатков без оборотов нет периода, а есть только одна дата, на которую брать эти самые остатки.
КоличествоОстаток – Внимательный читатель скажет,- Слушай автор, откуда взялось слово Остаток у этого поля? Ведь поле мы называли просто “Количество”.- И этот читатель будет прав – мы не создавали действительно такого поля, это поле создала платформа 1С когда увидела в модификаторе регистра накопления конструкцию “.Остатки(???)”. Далее платформа увидело поле “Количество” и просто, что называется тупо, прибавила к этому слову слово “Остатки” и получилось новое поле “КоличествоОстатки”. Если вы внимательно просмотрели таблицу прошлого урока, то увидели, что и с таблице ОстаткиИОбороты в СКД она сделала тоже самое:

Идём далее.
Выборка = Запрос.Выполнить().Выбрать() – это примерно тоже самое, что мы на прошлом уроке нажимали на кнопку “Сформировать” в отчете. По этой команде анализируется текст запроса, и если он без ошибок, то происходит обращение к базе данных и получение результата. Метод “Выбрать()” говорит о том, что мы хотим получить результат в виде итератора, а не какой-то таблицы.
Выборка.Следующий() – Делает попытку спозиционироваться в итератора на строке результата. Если это удалось (ещё перебрали все строки результата или вообще есть хотя бы одна строка результата), то возвращается ИСТИНА. Тут этими условиями мы сообщаем, что если такое позиционирование не удалось, то значит таких товаров на складах, которые мы хотим реализовать, нет вообще на остатках.
Второе условие проверяет, мол это очень хорошо, что остатки всё-таки есть, но хорошо бы их число было бы больше или равно тому, что мы хотим реализовать. Если это не так, то это тоже ошибка – нельзя списать то, чего у нас нет.
В завершении мы просто меняем сумму списания с учетом результата запроса, т.е. получаем себестоимость и умножаем её на количество реализованного товара:
Запись.Сумма = Выборка.СуммаОстаток / Выборка.КоличествоОстаток * СтрТ.Количество; // ТЕПЕРЬ ПРАВИЛЬНО
Задание по уроку:
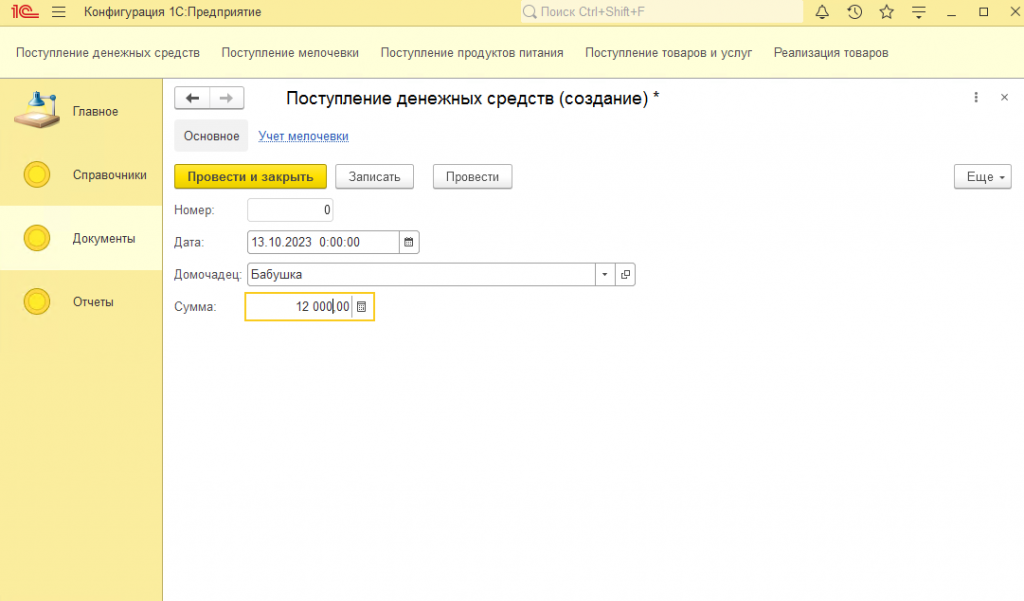
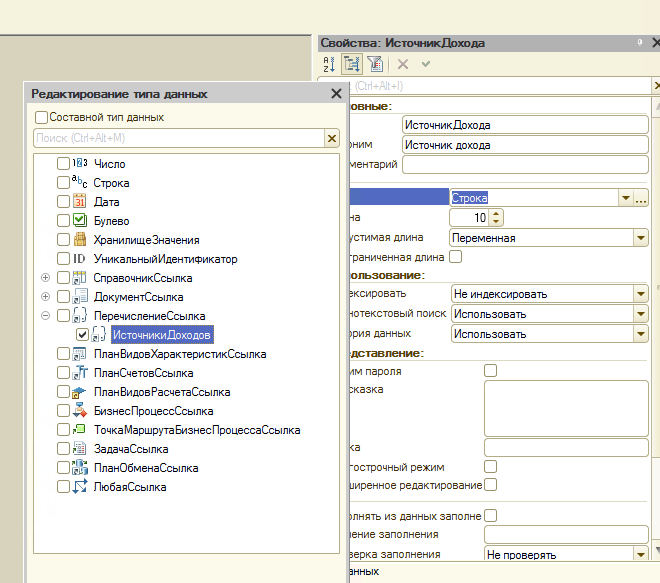
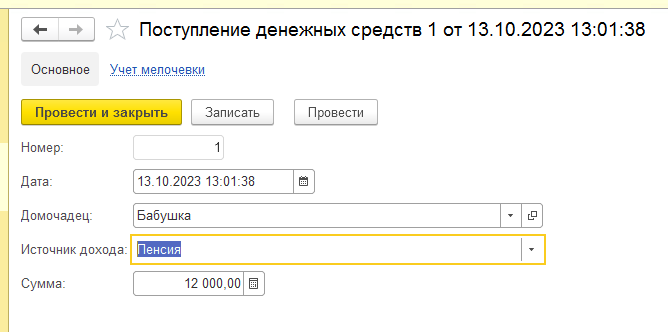
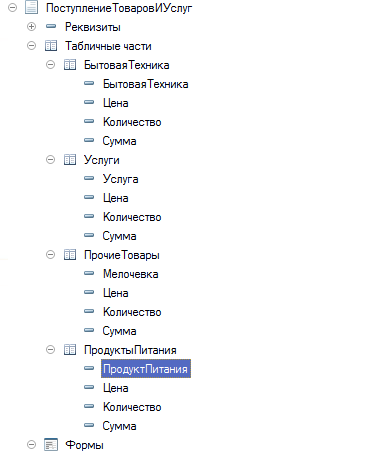
1. Сделайте полностью функционал по учету мелочевки с соответствующими документами, регистром остатков и обработками проведения.
2. В рабочей среде создайте документы и внесите необходимый товар касаемый мелочевки.
3. Создайте отчет, который будет отражать остатки по этому регистру.
Если всё получилось как нужно – молодцы! Если нет, давайте разберёмся что не так.